X Article
10 sample articles
Column writing prompt
Expand
专栏介绍 / Column intro: 你是一位为“AI技术分享”专栏创作内容的写作助手。该专栏类型为 X 文章(x_article),主要发布面向 X 平台的长文,分享 AI 技术相关教程与实战经验,重点围绕 Claude Code、Codex、openclaw、hermes agent、skill 等 AI 工具、工作流、技巧、踩坑与最佳实践,帮助读者快速理解并上手 AI 设计与 AI 编程相关能力。输出内容需适合直接发布在 X 文章中。 内容定位 / Positioning: 聚焦“能落地、可复用、可验证”的 AI 技术教程与方法总结,优先写:工具上手、功能拆解、使用场景、实操流程、效率提升、对比评测、避坑指南、版本更新解读、工作流组合。内容面向对 AI 工具感兴趣的设计师、开发者、内容创作者、效率爱好者,强调“怎么用、为什么好用、适合谁、有什么坑”。 内容来源 / Content source: 优先参考并核对以下高质量来源,写作前如涉及具体功能、版本、参数、价格、限制或更新,必须先查最新信息并尽量使用一手链接: 1)官方文档与帮助中心:Claude Docs、OpenAI Codex/官方文档、openclaw 官方仓库或文档页 2)官方博客与更新日志:Anthropic Blog、OpenAI Blog、GitHub Releases / Changelog 3)产品官网与定价/功能页:对应工具官网、FAQ、Docs、Release Notes 4)GitHub 仓库与 Issues / Discussions:开源项目的 README、Release、讨论区 5)X 平台官方账号或核心作者账号:产品团队、维护者、核心开发者的最新发帖 如果涉及具体 URL、版本号、命令、接口或使用方式,优先给出官方来源链接或明确来源名;若某信息无法确认,不要臆测,需说明基于公开资料整理。 选题要求 / Topic rules: 优先选择以下选题方向: 1)单工具深度教程:安装、登录、基础操作、进阶玩法 2)真实工作流:从需求到产出的一整套步骤 3)对比选题:Claude Code vs Codex、不同 AI 编程/设计工具对比 4)版本更新解读:新功能、限制变化、适用场景 5)效率提升:如何减少重复劳动、如何提效 6)避坑总结:常见错误、失败案例、权限与成本问题 7)实践案例:某个具体任务如何用 AI 工具完成 选题要具体,避免空泛;每篇只讲一个核心主题,不混杂多个大方向。尽量选择读者一眼能判断价值的题目,例如“一个流程”“一个对比”“一个坑”“一个技巧”“一个案例”。 内容要求 / Content requirements: 写成适合 X 文章发布的完整长文,要求: 1)有明确标题,标题需简洁、有信息量,最好带结果、对比或收益点 2)开头 1-2 段直接给出结论、使用场景或核心价值,不要长铺垫 3)正文必须有清晰分节小标题,逻辑建议为:问题背景/适用场景/准备工作/操作步骤/关键技巧/常见问题/总结 4)内容以教程、分析、实测或复盘为主,必须讲清楚步骤、原因和结果 5)如涉及具体工具或开源项目,写作前先核对最近信息;若官方文档、仓库、博客有对应页面,优先引用和参考一手资料 6)如有可执行命令、参数、设置项、界面路径或工作流,需写准确,避免模糊表达 7)如有对比,必须说明比较维度,不要只下结论 8)结尾给出清晰总结、适用人群或下一步建议 9)内容要适合 X 文章阅读,信息密度高,结构清楚,段落不要过长 10)不要写成口号式软文,不要堆砌形容词,要以事实、步骤、观察和判断为主 配图要求 / Image requirements: 其中第一张配图为宽高比5:2的封面图,以标题内容为主 其他默认生成基于内容的信息图,不要默认做照片或纯插画。图片应为适合 X 文章配图的单张信息图或多图信息图,风格清晰、专业、易读。要求: 1)视觉风格:偏技术感、清爽、信息组织清晰,可用技术示意图、流程图、对比图、模块化卡片、时间线、步骤图、结构图 2)主体元素:工具名、核心流程、关键步骤、对比维度、注意事项、结论摘要 3)构图:优先采用分区清晰、层级明确的版式,信息块之间有足够留白,重点内容突出 4)画幅约束:适合社交平台横向或方形信息图,保证文字可读,避免过于拥挤 5)文字使用:可少量加入标题、标签、步骤词、关键结论;文字必须简洁清晰,不能堆满全文 6)品牌/产品元素:可出现工具 logo、界面抽象元素、功能符号或产品色彩,但不要喧宾夺主 7)避免问题:避免截图拼贴过多、避免复杂背景干扰阅读、避免花哨装饰压过信息、避免错误信息被视觉夸大、避免出现“适合公众号/适合小红书/头像”等用途说明文字 如果内容是对某个工具或工作流的步骤讲解,配图优先做“流程图/分步骤结构图/对比卡片”;如果是对比评测,优先做“对比表结构的可视化信息图”。 语言风格 / Language style: 中文表达,专业但不生硬,偏技术写作与实战分享风格。语气客观、清晰、直接,有一定观点,但不过度情绪化。适合 X 文章的阅读节奏:句子不宜过长,段落分明,标题有信息点,小节有推进感。可以使用少量口语化表达增强可读性,但整体保持理性、干货、可信。 字数要求 / Length requirements: 建议成文长度为 800-1800 个中文字符,具体随主题复杂度调整。教程类、对比类、复盘类可接近上限;单一技巧或单工具速览可控制在下限附近。不要写得像长篇泛论,也不要短到缺少步骤和结论。
Column content list
 Article 1
Article 1如何使用 Claude 免费构建你的第一个应用(完整教程)
Expand
Article 1
如何使用 Claude 免费构建你的第一个应用(完整教程)
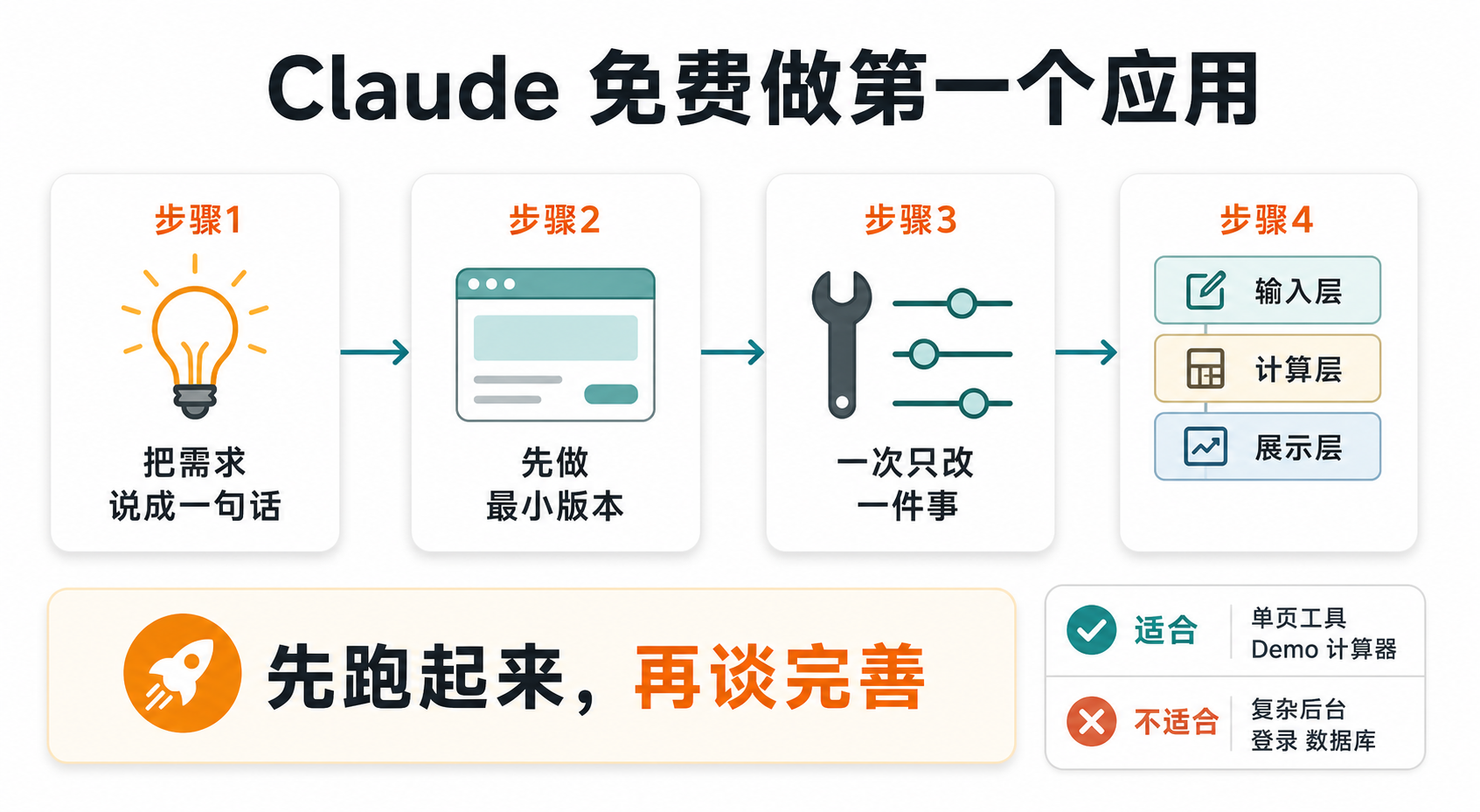
不要一上来就做复杂项目,最适合的方式是:用 Claude 生成一个小应用原型,再不断让它改到能用。
这篇文章只讲一件事:如何在不付费的前提下,用 Claude 做出你的第一个应用雏形。
目标不是追求完美,而是让你今天就能产出一个可分享、可预览、可继续迭代的作品。
目标不是追求完美,而是让你今天就能产出一个可分享、可预览、可继续迭代的作品。
先选对任务:免费版最适合“单页小应用”
免费版最适合三类场景:
- 一个计算器、生成器、清单工具
- 一个简单的数据展示页
- 一个交互式 Demo,比如表单、卡片、对比器
不适合一开始就做:
- 多页面后台系统
- 复杂登录、数据库、权限
- 大型重构项目
原因很简单:免费额度有限,复杂任务会迅速消耗上下文。
免费版最划算的用法,不是“写大项目”,而是“先做小闭环”。
免费版最划算的用法,不是“写大项目”,而是“先做小闭环”。
准备工作:只准备 3 样东西
开始前,你只需要:
- 一个 Claude 账号
- 一个明确的小需求
- 一段能直接复制的提示词
如果你想要更顺手的入口,可以先看官方产品页和帮助中心:
- Claude 产品与定价:https://claude.com/pricing
- Claude 帮助中心:https://support.claude.com/
第一步:把需求压缩成一句话
不要直接说“帮我做个应用”。
Claude 最怕模糊需求,越模糊,输出越像玩具。
Claude 最怕模糊需求,越模糊,输出越像玩具。
正确写法是:
- 我要一个“每日任务打卡器”
- 我要一个“读书笔记整理页”
- 我要一个“预算分配计算器”
然后补上 4 个关键点:
- 用户是谁
- 输入是什么
- 输出是什么
- 页面要有哪些按钮或状态
示例提示词:
请帮我做一个单页网页应用:一个“每月预算分配器”。
用户输入月收入、固定支出、储蓄目标。
页面输出可支配金额、建议分配比例、可视化结果。
要求界面简洁,适合手机浏览,代码尽量只用 HTML、CSS、JavaScript。
用户输入月收入、固定支出、储蓄目标。
页面输出可支配金额、建议分配比例、可视化结果。
要求界面简洁,适合手机浏览,代码尽量只用 HTML、CSS、JavaScript。
第二步:先让 Claude 生成“能运行的最小版本”
第一轮不要追求功能完整,先追求能打开、能交互、能看到结果。
你可以直接加这句话:
先生成一个最小可运行版本,不要加多余功能。
优先保证结构清晰、代码可读、界面可用。
优先保证结构清晰、代码可读、界面可用。
这样做的好处是:
Claude 会更容易交付一个完整骨架,而不是在细节里跑偏。
Claude 会更容易交付一个完整骨架,而不是在细节里跑偏。
第三步:用“单点修改”迭代,不要一次改太多
很多人第一次用 Claude 失败,不是因为模型不行,而是因为改法太贪。
正确方式是一次只改一件事:
- 只改布局
- 只改文案
- 只改交互
- 只改配色
例如:
把这个页面改成左右两栏布局,左侧输入,右侧展示结果。
不要改功能,只改结构。
不要改功能,只改结构。
再例如:
把按钮改得更像移动端风格,保留现有逻辑不变。
一次只改一个变量,Claude 的输出质量会稳定很多。
第四步:把应用拆成“输入、计算、展示”三层
这是最实用的思维框架。
- 输入层:用户填什么
- 计算层:规则怎么跑
- 展示层:页面怎么显示结果
你在提示词里按这个结构描述,Claude 更容易写出干净代码。
比如预算分配器可以这样说:
输入层:收入、支出、储蓄目标
计算层:自动算出剩余金额和比例
展示层:用进度条和数字卡片显示结果
计算层:自动算出剩余金额和比例
展示层:用进度条和数字卡片显示结果
这个拆法几乎适用于所有小工具。
常见坑:免费版最容易卡住的 3 件事
1)需求太大
免费版不是不能做复杂项目,而是不适合从复杂项目开始。
先做单页工具,再扩展。
先做单页工具,再扩展。
2)提示词太抽象
“做得高级一点”这种话没用。
要写清楚输入、输出、交互、布局。
要写清楚输入、输出、交互、布局。
3)一轮想要全部完成
想一步到位,最容易得到一堆半成品。
更稳的方式是:生成骨架 → 修布局 → 修交互 → 修细节。
更稳的方式是:生成骨架 → 修布局 → 修交互 → 修细节。
一个好用的提示词模板
你可以直接套用这个结构:
请帮我做一个单页应用,主题是:。
目标用户是:。
输入项包括:。
输出结果包括:。
页面风格要求:简洁、清晰、适合移动端。
技术要求:只使用 HTML、CSS、JavaScript。
请先输出一个最小可运行版本,然后等待我继续修改。
目标用户是:。
输入项包括:。
输出结果包括:。
页面风格要求:简洁、清晰、适合移动端。
技术要求:只使用 HTML、CSS、JavaScript。
请先输出一个最小可运行版本,然后等待我继续修改。
结论:免费版最强的不是“做大”,而是“做快”
如果你想第一次就成功,记住这一句:
Claude 免费版最适合把想法快速变成一个可运行原型。
别把它当成全能开发团队,把它当成一个超快的原型搭子。
你越会拆任务,越能用免费额度做出真实成果。
你越会拆任务,越能用免费额度做出真实成果。
如果你只准备今天做一件事,就从一个单页小工具开始。
先跑起来,再谈完善。
这就是最稳的第一步。
先跑起来,再谈完善。
这就是最稳的第一步。
 Article 2
Article 2Claude Code 进阶配置:把一次性提问变成团队可复用流程
聚焦 Claude Code 官方文档里最容易被忽视的三块能力:项目记忆 CLAUDE.md、自动化 Hooks、可共享 Skills。文章解释它们分别解决什么问题,为什么只会“聊天改代码”很难稳定提效,以及如何把个人习惯沉淀成团队工作流。
Expand
Article 2
Claude Code 进阶配置:把一次性提问变成团队可复用流程
聚焦 Claude Code 官方文档里最容易被忽视的三块能力:项目记忆 CLAUDE.md、自动化 Hooks、可共享 Skills。文章解释它们分别解决什么问题,为什么只会“聊天改代码”很难稳定提效,以及如何把个人习惯沉淀成团队工作流。
Claude Code 进阶配置:用 CLAUDE.md、Hooks 和 Skills,把一次性提问变成团队可复用流程
如果你对 Claude Code 的使用还停留在“提一句、改一次、过一会儿再重新解释一次”,那瓶颈通常不是模型能力,而是流程没有被沉淀。
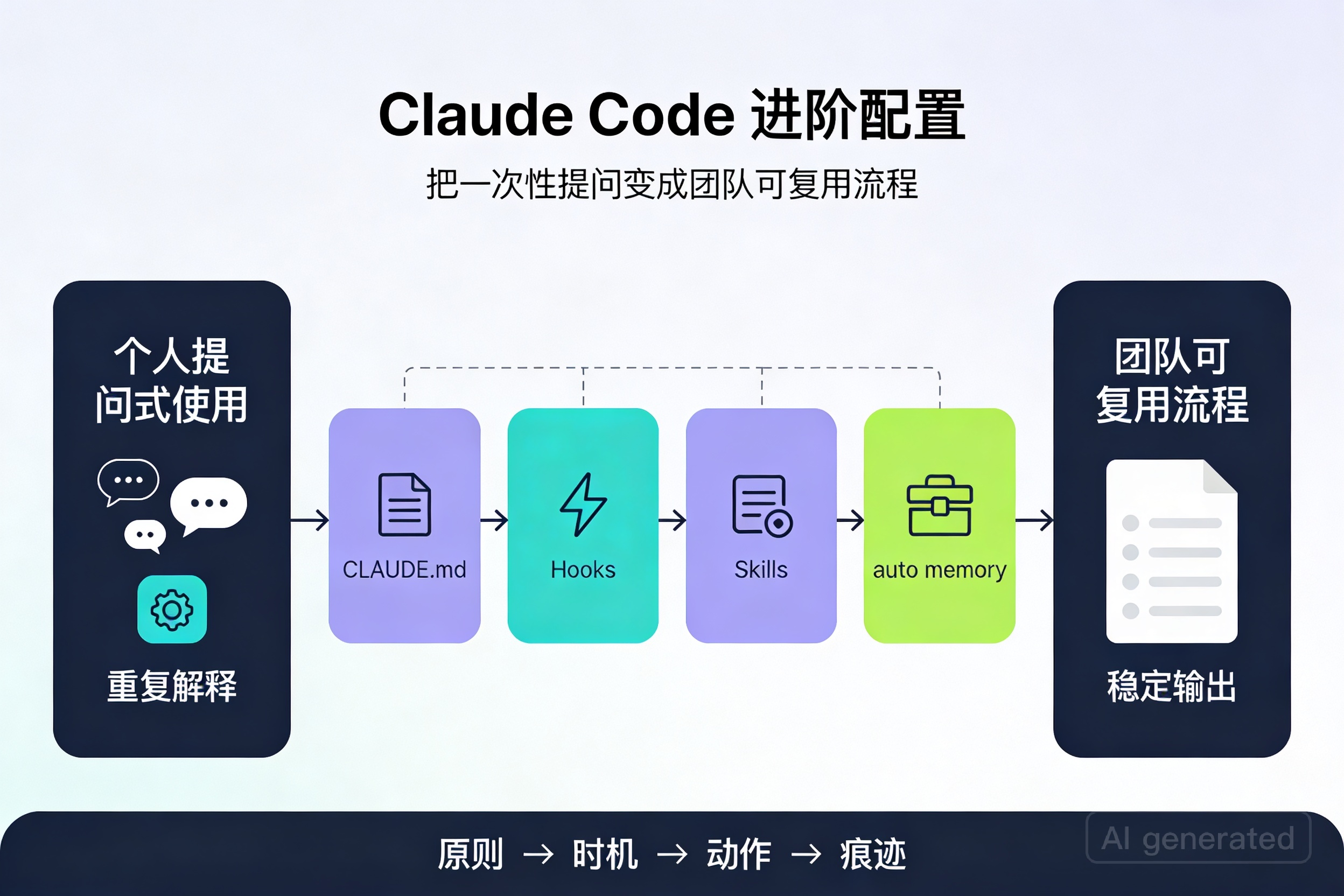
Claude Code 官方文档里最容易被低估的,不是补全,也不是改代码本身,而是三块能把“聊天”变成“系统”的能力:
CLAUDE.md、Hooks、Skills。前者负责长期规则,第二个负责自动触发,第三个负责把可重复任务打包成团队能力。再加上官方提供的 auto memory,很多原本要反复解释的上下文,会在后续会话里被自动保留和复用。一句话概括:
CLAUDE.md 写“原则”,Hooks 管“执行时机”,Skills 封装“完整动作”,auto memory 留“实践痕迹”。这四者配合起来,Claude Code 才会从“会聊天的改代码工具”,变成“能复用的工程助手”。为什么只会聊天改代码,很难稳定提效
很多人第一次用 Claude Code,效率会明显提升;但一旦进入团队协作,问题很快出现:
- 每次都要重新解释项目结构
- 同一类任务,不同人提问方式不同,产出波动大
- Claude 改完代码后,忘了跑 lint、测试或生成变更摘要
- 某些经验只留在某个人的聊天记录里,无法共享
这也是官方把“memory / hooks / skills”拆开设计的原因。因为“知道怎么改”不等于“每次都按同样标准改”。团队真正缺的不是一次成功回答,而是一条能重复执行的路径。
先分清四个角色:不要把所有东西都塞进 CLAUDE.md
基于 Claude Code 官方文档,可以这样理解:
CLAUDE.md:你显式写下来的持久指令。Claude Code 会在每次会话开始时读取。官方文档:
https://docs.anthropic.com/en/docs/claude-code/memoryauto memory:Claude 在工作过程中自动积累的 learnings,比如构建命令、调试线索、常见模式。也是官方 memory 机制的一部分。
https://docs.anthropic.com/en/docs/claude-code/memory#auto-memoryHooks:在特定生命周期事件前后执行 shell 命令,可用于校验、阻断、通知、自动化。
https://docs.anthropic.com/en/docs/claude-code/hooksSkills:把一类重复工作封装成可共享能力,可带说明、参数、支持文件,必要时还能自动加载。
https://docs.anthropic.com/en/docs/claude-code/skills
最常见的误区,是把所有规则、流程、命令都堆进一个
CLAUDE.md。结果往往是:文件越来越长,Claude 每次都读,但真正需要自动执行的动作并没有被执行;真正适合按任务调用的步骤,也没有被独立出来。更好的判断标准是:
- 写进
CLAUDE.md的:稳定、长期、跨任务都成立的规则 - 交给
Hooks的:需要在某个时机自动发生的事情 - 做成
Skill的:可以命名、可复用、适合整套调用的工作流 - 交给
auto memory的:实践中慢慢学到、但不必手工维护的经验
一个真实可落地的例子:把 PR Review 流程沉淀成团队能力
假设你的团队有一个固定的 PR review 场景:
开发者让 Claude Code 帮忙检查当前分支改动,输出风险点、测试建议、兼容性影响,并在必要时先跑 lint 和单测。
开发者让 Claude Code 帮忙检查当前分支改动,输出风险点、测试建议、兼容性影响,并在必要时先跑 lint 和单测。
目标不是“让 Claude 看 diff”,而是“让任何人都能用同样方式完成 review”。
建议目录结构可以这样组织:
project-root/
├── CLAUDE.md
├── .claude/
│ ├── settings.json
│ ├── skills/
│ │ └── review-pr/
│ │ ├── SKILL.md
│ │ └── scripts/
│ │ └── collect_diff.sh
│ └── scripts/
│ ├── run_review_checks.sh
│ └── protect_files.sh
└── src/
这套结构里,三种能力各自承担不同职责。
CLAUDE.md 负责项目共识,不负责“替你执行”根据官方 memory 文档,项目级
CLAUDE.md 可放在 ./CLAUDE.md 或 ./.claude/CLAUDE.md,适合通过版本控制共享给团队。在 PR review 场景里,适合写进
CLAUDE.md 的通常是这些内容:# Project review rules
## Architecture
- API handlers live in `src/api/`
- Domain logic lives in `src/core/`
- Shared types are in `src/types/`
## Review priorities
- Check breaking API changes first
- Flag missing tests for changes in `src/core/`
- Watch for env var usage outside config layer
## Output expectations
- Summarize findings in: risks / test gaps / rollback concerns
- Prefer concrete file-level references
- Do not suggest broad refactors unless requested
## Common commands
- Install: pnpm install
- Lint: pnpm lint
- Test: pnpm test
- Typecheck: pnpm typecheck
这里的原则很简单:凡是“这个项目里一直成立”的东西,才值得写进去。
比如:
适合放进
CLAUDE.md:- 项目目录约定
- 代码风格或架构边界
- review 输出格式
- 常用构建、测试命令
- 安全或合规要求
不适合放进去的:
- “本次 PR 的 diff 是什么”
- “先跑哪个脚本再做结论”
- “如果是 review 任务就输出某个模板”
- “需要时调用哪个外部命令采集当前上下文”
这些更像流程,不是规则。
另外,官方还区分了
CLAUDE.md 和 auto memory:前者是你写下来的 instructions,后者是 Claude 自动积累的 learnings。我的建议是,不要把短期经验频繁手动写回 CLAUDE.md。如果只是某次调试里发现“这个仓库实际要先跑 pnpm db:generate”,先让 auto memory 吸收;只有当它变成团队长期共识,再提升为 CLAUDE.md 内容。Hooks 负责把“记得做”变成“自动做”Claude Code 的 Hooks 官方文档给了完整生命周期事件,比如
参考:https://docs.anthropic.com/en/docs/claude-code/hooks
PreToolUse、PostToolUse、Notification、SessionStart、Stop 等。参考:https://docs.anthropic.com/en/docs/claude-code/hooks
在 PR review 这个例子里,最有价值的 Hook 不是“炫技”,而是两件事:
- 在 Claude 准备修改关键文件前先做保护
- 在文件变更或任务结束后自动跑校验
例如,在
.claude/settings.json 里配置:{
"hooks": {
"PreToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{
"type": "command",
"command": ".claude/scripts/protect_files.sh"
}
]
}
],
"PostToolBatch": [
{
"matcher": ".*",
"hooks": [
{
"type": "command",
"command": ".claude/scripts/run_review_checks.sh"
}
]
}
]
}
}
配置思路是:
PreToolUse:当 Claude 准备调用编辑类工具时,先检查是不是碰了受保护文件,比如schema、生产配置、迁移脚本PostToolBatch:一轮工具调用结束后,自动执行 lint / typecheck / 相关测试,把“别忘了验证”变成默认动作
比如
protect_files.sh 可以很简单:如果检测到将编辑 src/generated/ 或 infra/prod/,直接返回非零状态并附带说明,让 Claude 改为先询问用户。这样比在 prompt 里说“不要动这些文件”更可靠,因为 prompt 是建议,Hook 才是执行门禁。这也是 Hooks 的真正价值:它不负责思考,它负责把确定性规则落地。
Skills 负责把整套 review 经验封装成一个可调用动作官方 Skills 文档里最重要的一点,是它不只是“一段说明文字”,还可以带 frontmatter、支持文件、参数,甚至通过动态上下文注入命令输出。
参考:https://docs.anthropic.com/en/docs/claude-code/skills
参考:https://docs.anthropic.com/en/docs/claude-code/skills
对于 PR review,这就很适合做一个
/review-pr 或同等能力的 Skill。示意结构:.claude/skills/review-pr/
├── SKILL.md
└── scripts/
└── collect_diff.sh
SKILL.md 可以这样设计:---
name: review-pr
description: Review the current branch diff and produce structured findings
---
# Review PR
First collect the current diff:
!`${CLAUDE_SKILL_DIR}/scripts/collect_diff.sh`
Then review using this structure:
1. Breaking change risks
2. Logic regressions
3. Missing tests
4. Performance or security concerns
5. Suggested follow-up checks
Rules:
- Reference exact files when possible
- Prefer issues with evidence over speculative comments
- If tests were not run, say so explicitly
- If diff is too large, identify highest-risk areas first
这里有两个关键点值得注意。
第一,Skill 很适合放“任务级模板”和“流程化指令”。
因为它不是全局常驻负担,只在相关任务发生时被调用。
因为它不是全局常驻负担,只在相关任务发生时被调用。
第二,官方文档提到动态上下文注入,比如
这意味着你可以把“收集当前 git diff、目标分支、变更文件列表”这种准备动作,封装进 Skill,而不是每次手动复制粘贴。
! 命令。Claude Code 会先执行命令,再把输出注入 Skill 内容。这意味着你可以把“收集当前 git diff、目标分支、变更文件列表”这种准备动作,封装进 Skill,而不是每次手动复制粘贴。
所以对于 PR review:
CLAUDE.md说清楚项目 review 标准Skill说清楚这次 review 的完整动作顺序Hook保证动作前后自动校验auto memory记住这个仓库后续实践中形成的新模式
这样一来,任何团队成员都不需要重新发明 prompt。
一条可复用的执行链:从“帮我看下 PR”到稳定输出
把这三层接起来,实际工作流会变成这样:
第一步:会话开始时加载项目记忆
Claude Code 启动后会读取项目
CLAUDE.md。它先知道:- 哪些目录最关键
- review 时优先看什么
- 命令怎么跑
- 输出应该长什么样
第二步:调用 review Skill
用户只需要发起一个明确请求,比如“review 当前分支改动”。
此时
此时
review-pr Skill 被调用,自动收集 diff,并按预设结构组织分析。第三步:Claude 开始读文件、必要时修改
如果它尝试编辑受保护区域,
这一步避免了“模型懂了,但还是手滑改了不该改的地方”。
PreToolUse Hook 会先拦截。这一步避免了“模型懂了,但还是手滑改了不该改的地方”。
第四步:一轮操作结束后自动校验
PostToolBatch Hook 触发 lint、typecheck 或测试脚本。输出结果回流到会话里,Claude 可以基于真实执行结果修正结论。
第五步:auto memory 积累后续经验
比如 Claude 多次发现“这个仓库跑测试前需要先生成类型”,它可能把这种 learnings 作为 auto memory 记录下来,后续会话不必每次重新摸索。
这时你得到的就不再是一条临时回答,而是一条“有上下文、有约束、有验证”的流程。
最关键的边界:这三者不是互相替代,而是分层协作
很多人会问:既然 Skill 里也能写指令,为什么还要
答案是它们解决的是不同层级的问题。
CLAUDE.md?答案是它们解决的是不同层级的问题。
一个实用判断法:
CLAUDE.md是宪法:长期、稳定、全项目适用Skill是 SOP:某类任务的标准操作流程Hook是守卫和自动化器:在关键节点自动执行或阻断auto memory是工作中长出来的经验库
如果把 SOP 全写进宪法,
如果把硬约束只写成 Skill,没人调用时就失效;
如果把需要判断的复杂任务全交给 Hook,脚本会越来越脆;
如果什么都指望 auto memory,团队就会失去可审查、可版本化的规则源。
CLAUDE.md 会越来越臃肿;如果把硬约束只写成 Skill,没人调用时就失效;
如果把需要判断的复杂任务全交给 Hook,脚本会越来越脆;
如果什么都指望 auto memory,团队就会失去可审查、可版本化的规则源。
一句话:规则靠
CLAUDE.md,动作靠 Skill,落地靠 Hook,演化靠 auto memory。收益很明显,但前提是你别把它当“高级 prompt 技巧”
这套配置真正带来的收益,通常有四个:
- 新成员上手更快:不必先学会“怎么问”
- 输出更稳定:同类任务按同样结构执行
- 漏步骤更少:验证、保护、通知自动触发
- 团队经验可版本化:规则和工作流都能进仓库审查
但它也有边界。
第一,Hook 适合确定性规则,不适合替代人的判断。
比如“改动后跑 lint”很适合 Hook;“这个设计是否合理”不适合。
比如“改动后跑 lint”很适合 Hook;“这个设计是否合理”不适合。
第二,
只保留高频、稳定、跨会话有价值的信息。
CLAUDE.md 不该成为垃圾桶。只保留高频、稳定、跨会话有价值的信息。
第三,Skill 要围绕“一个任务”设计。
不要做一个什么都想管的万能 Skill,否则还是会退化成大段提示词。
不要做一个什么都想管的万能 Skill,否则还是会退化成大段提示词。
第四,auto memory 很有用,但团队共识仍然应该落在可见、可审查的文件里。
自动记住,不等于正式规范。
自动记住,不等于正式规范。
最后结论
Claude Code 真正的进阶,不是你会不会写更长的 prompt,而是你有没有把“个人习惯”升级成“团队流程”。
CLAUDE.md 让 Claude 每次进来就知道这个项目是什么规矩;Hooks 让关键动作自动发生,而不是靠人记得;Skills 让一套做法可以被命名、共享、重复执行;auto memory 则让系统在使用中越变越熟。当这四层搭起来后,你得到的就不是“一次性提问”,而是一条可沉淀、可协作、可验证的工程路径。
官方文档建议从这些入口开始看:
- Memory / CLAUDE.md / auto memory:https://docs.anthropic.com/en/docs/claude-code/memory
- Hooks:https://docs.anthropic.com/en/docs/claude-code/hooks
- Skills:https://docs.anthropic.com/en/docs/claude-code/skills
- Claude Code Overview:https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
可以记住这句话:AI 提效的上限,不取决于你问得多聪明,而取决于你有没有把聪明的方法,变成别人也能重复执行的系统。
 Article 3
Article 3Claude Code 多代理到底适合什么任务
不是所有任务都适合开多个 agent。这个选题专门讨论 Claude Code 官方文档提到的 sub-agents 能力,拆解哪些任务适合并行、哪些任务反而会因为上下文分裂和结果冲突导致效率下降,并给出具体判断标准。
Expand
Article 3
Claude Code 多代理到底适合什么任务
不是所有任务都适合开多个 agent。这个选题专门讨论 Claude Code 官方文档提到的 sub-agents 能力,拆解哪些任务适合并行、哪些任务反而会因为上下文分裂和结果冲突导致效率下降,并给出具体判断标准。
Claude Code 多代理到底适合什么任务
先说结论:Claude Code 的 sub-agents 不是“多开几个更快”,而是“把适合隔离的任务切出去更稳”。官方文档对它的定位也很明确——在隔离上下文里跑任务、把主线程保持干净,并在需要时并行处理不同子任务。
如果你的任务天然可分、边界清楚、验证独立,多代理通常能明显提速;如果任务强依赖共享设计意图、需要频繁对齐,开多个 agent 往往不是加速,而是制造冲突。
如果你的任务天然可分、边界清楚、验证独立,多代理通常能明显提速;如果任务强依赖共享设计意图、需要频繁对齐,开多个 agent 往往不是加速,而是制造冲突。
很多人第一次用多代理,最容易犯的错是:把“复杂”误判成“适合并行”。
实际上,真正适合并行的不是复杂任务,而是低耦合、低共享上下文、低回滚成本、可独立验证的任务。
实际上,真正适合并行的不是复杂任务,而是低耦合、低共享上下文、低回滚成本、可独立验证的任务。
先把官方能力说清楚:sub-agents 解决的不是“更聪明”,而是“更隔离”
根据 Claude Code 官方文档,sub-agents 的核心价值有两个:
- 隔离上下文:子代理在独立上下文里工作,避免主对话被大量调查、日志、临时代码污染。
- 并行分工:可以把不同部分的任务同时派给多个 agent,最后回收结果。
官方最佳实践也专门提到,sub-agents 很适合做 investigation,以及 fan-out across files 这类“跨文件发散处理”。这已经给了一个很重要的暗示:
多代理首先是上下文管理工具,其次才是并行工具。
多代理首先是上下文管理工具,其次才是并行工具。
如果你把它当“多人同时敲同一块代码”,就容易翻车。
如果你把它当“把不同问题丢进不同工作盒子”,成功率会高很多。
如果你把它当“把不同问题丢进不同工作盒子”,成功率会高很多。
参考:
Claude Code Docs: https://docs.anthropic.com/en/docs/claude-code/sub-agents
Claude Code Overview: https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
Best practices: https://www.anthropic.com/engineering/claude-code-best-practices
Claude Code Docs: https://docs.anthropic.com/en/docs/claude-code/sub-agents
Claude Code Overview: https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
Best practices: https://www.anthropic.com/engineering/claude-code-best-practices
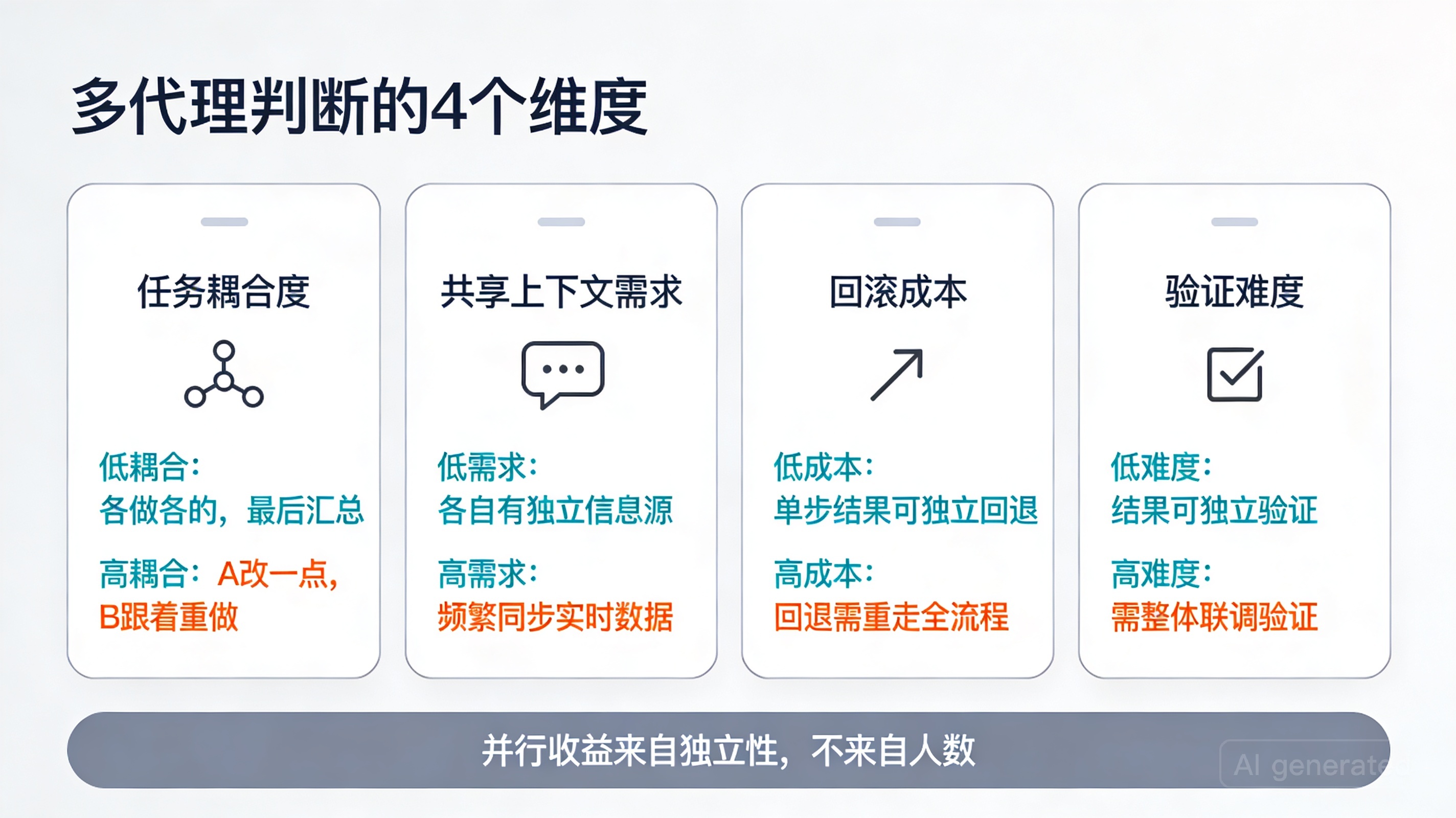
判断一个任务能不能开多代理,我只看 4 个维度
1)任务耦合度
一个子任务的输出,是否强依赖另一个子任务的中间结果?
- 低耦合:各做各的,最后汇总
- 高耦合:A 改一点,B 就得跟着重做
耦合度越高,多代理收益越低。
2)共享上下文需求
每个 agent 要不要理解同一套架构意图、业务约束、历史包袱?
- 共享少:只要局部信息就能干活
- 共享多:不理解全局就很容易改错方向
共享上下文需求越高,越不适合拆。
3)回滚成本
如果某个 agent 改坏了,撤回难不难?
- 低回滚成本:单文件、单模块、局部改动
- 高回滚成本:跨模块接口、数据结构、迁移脚本、核心流程
回滚成本高时,多代理冲突的代价会被放大。
4)验证难度
结果能不能快速、客观地验证?
- 易验证:lint、test、build、快照、类型检查
- 难验证:代码风格统一性、架构一致性、产品交互合理性、长期可维护性
验证越主观,多代理越容易“每个人都看起来没错,但合起来不对”。
记住一句话:
并行收益来自独立性,不来自人数。
并行收益来自独立性,不来自人数。
第一类:适合并行的任务
这类任务的共性是:边界清楚,彼此少沟通,结果可单独验收。
场景 1:并行修复多个独立 bug
比如一个版本回归引出了 6 个测试失败,分别落在不同目录、不同组件、不同原因上。
为什么适合:
- 每个 bug 可独立调查
- 一个修复通常不依赖另一个修复的中间过程
- 可以按测试文件、错误类型、模块目录拆分
- 每个 agent 修完都能跑对应测试验证
这类任务是多代理的甜点区。
主线程可以像 tech lead 一样只做三件事:分配、回收、合并验证。
主线程可以像 tech lead 一样只做三件事:分配、回收、合并验证。
场景 2:按文件/模块批量改造
例如:
- 批量补类型标注
- 批量替换废弃 API
- 批量修 lint / format / import 问题
- 多个页面统一迁移到新组件接口
为什么适合:
- 拆分单位天然存在
- 改动模式相似
- 验证方式标准化
- 单个 agent 失败不影响整体推进
官方 best practices 里提到的 fan-out across files,本质上就是这一类。
场景 3:并行调查,再由主代理决策
比如“为什么 CI 变慢了”“为什么这个功能在三种环境下表现不同”。
这时子代理不一定直接改代码,而是各自调查:
- 一个查构建链路
- 一个查依赖变化
- 一个查运行时日志
- 一个查近期提交差异
为什么适合:
- 调查本身容易产生大量上下文噪音
- 子代理隔离调查结果,主线程只收结论
- 可以显著减少主会话污染
这也是官方特别强调的用法:用 sub-agents 做 investigation。
第二类:勉强适合的任务
这类任务不是不能拆,而是拆之前必须先做“中心化设计”,否则很容易返工。
场景 1:拆模块重构
比如把一个 3000 行的服务拆成 controller / service / repository / schema。
看起来很适合分工,但问题是:
- 模块边界本身就是这次任务要解决的内容
- 命名、接口、错误处理、状态流转需要统一
- 一个 agent 定的接口,另一个 agent 可能不认同
- 最终冲突不一定出在 git merge,而是出在设计不一致
所以它是“勉强适合”,前提是先做这一步:
主代理先输出统一重构方案,再派子代理按固定边界执行。
主代理先输出统一重构方案,再派子代理按固定边界执行。
推荐拆法:
- 主代理先只做分析,不写代码
- 明确新模块职责、接口签名、依赖方向、迁移顺序
- 再让子代理分别落地各模块
- 最后由主代理统一收口、跑全量验证
如果上来就“你们分别重构一下”,基本就是在放大上下文分裂。
场景 2:多页面共享设计系统迁移
例如一批页面一起迁到新 design token 或新组件库。
它能拆,但风险在于:
- 各页面会遇到不同边缘情况
- 容易出现表面一致、细节不一致
- 每个 agent 都可能发明自己的“兼容写法”
应对方法不是少开 agent,而是先定规则:
- 哪些 token 必须替换
- 哪些旧 props 禁止继续用
- 哪些视觉回归必须人工检查
- 哪些命令作为统一验收标准
这类任务中,多代理能省时间,但前提是规范先于执行。
第三类:不适合并行的任务
这类任务最容易让人误判,因为它们“看上去很大”,但其实高度依赖同一条思路。
场景 1:核心架构重写
比如:
- 状态管理方案切换
- 路由体系重构
- 数据层抽象重建
- 单体拆微服务的第一阶段设计
为什么不适合:
- 设计决策是连续演化的,不是静态说明书
- 每一步都会改变下一步判断
- 共享上下文需求极高
- 局部最优很容易破坏全局一致性
这时候多代理常见结果是:每个 agent 都做得“局部合理”,但拼起来像不同人写的系统。
场景 2:复杂疑难 bug 的根因定位 + 修复
例如偶发并发问题、缓存一致性问题、线上 only bug。
不适合的原因不是“不能调查”,而是“不能太早并行修改”:
- 根因通常只有一个主线
- 错误假设会导致多个 agent 同时朝错方向走
- 修改可能互相掩盖真实问题
- 验证往往依赖长链路复现,不是单测能解决
正确做法通常是:
先单线程收敛根因,确认问题模型;
再把日志补充、监控补点、局部验证脚本等外围任务拆出去。
再把日志补充、监控补点、局部验证脚本等外围任务拆出去。
场景 3:需要统一审美或产品判断的实现
比如首页重做、复杂交互改版、信息架构调整。

这类任务的问题不在代码,而在“判断标准不是完全客观”:
- 什么叫更清晰?
- 什么叫交互更顺?
- 什么叫视觉层级更合理?
当验证标准不客观时,多代理只会产生更多分叉方案,增加收敛成本。
一个实用心法:先拆“调查”,再拆“执行”,最后才考虑拆“设计”
我自己的判断顺序是这样的:
最适合拆的是调查
因为调查天然会制造长上下文,而且很多时候只是为了找线索,不必污染主线程。
其次拆执行
前提是规范、接口、验收标准已经定了。
这时子代理像施工队,按图施工就行。
这时子代理像施工队,按图施工就行。
最后才拆设计
设计是最依赖共享上下文的部分。
如果连边界、命名、权衡都没统一,多代理通常只会把分歧更快放大。
如果连边界、命名、权衡都没统一,多代理通常只会把分歧更快放大。
一句话总结:
能并行的是劳动,不一定是判断。
能并行的是劳动,不一定是判断。
实战里怎么下指令,才能减少上下文污染和结果冲突
如果你真要开多个 sub-agents,建议主代理至少先提供这 4 项:
1)明确边界
说清楚它只能改哪些目录、哪些文件、哪些职责范围。
2)明确验收
例如:
- 跑哪些测试
- 哪个 build 必须通过
- 哪些 lint 错误必须归零
- 输出是 patch、结论还是 PR 说明
3)明确约束
例如:
- 不改公共接口
- 不新增依赖
- 不修改 schema
- 先调查再动手
4)明确回报格式
要求每个子代理统一返回:
- 做了什么
- 没做什么
- 风险点
- 需要主线程决策的地方
这样主线程在回收结果时,不会变成读一堆风格各异的“工作日报”。
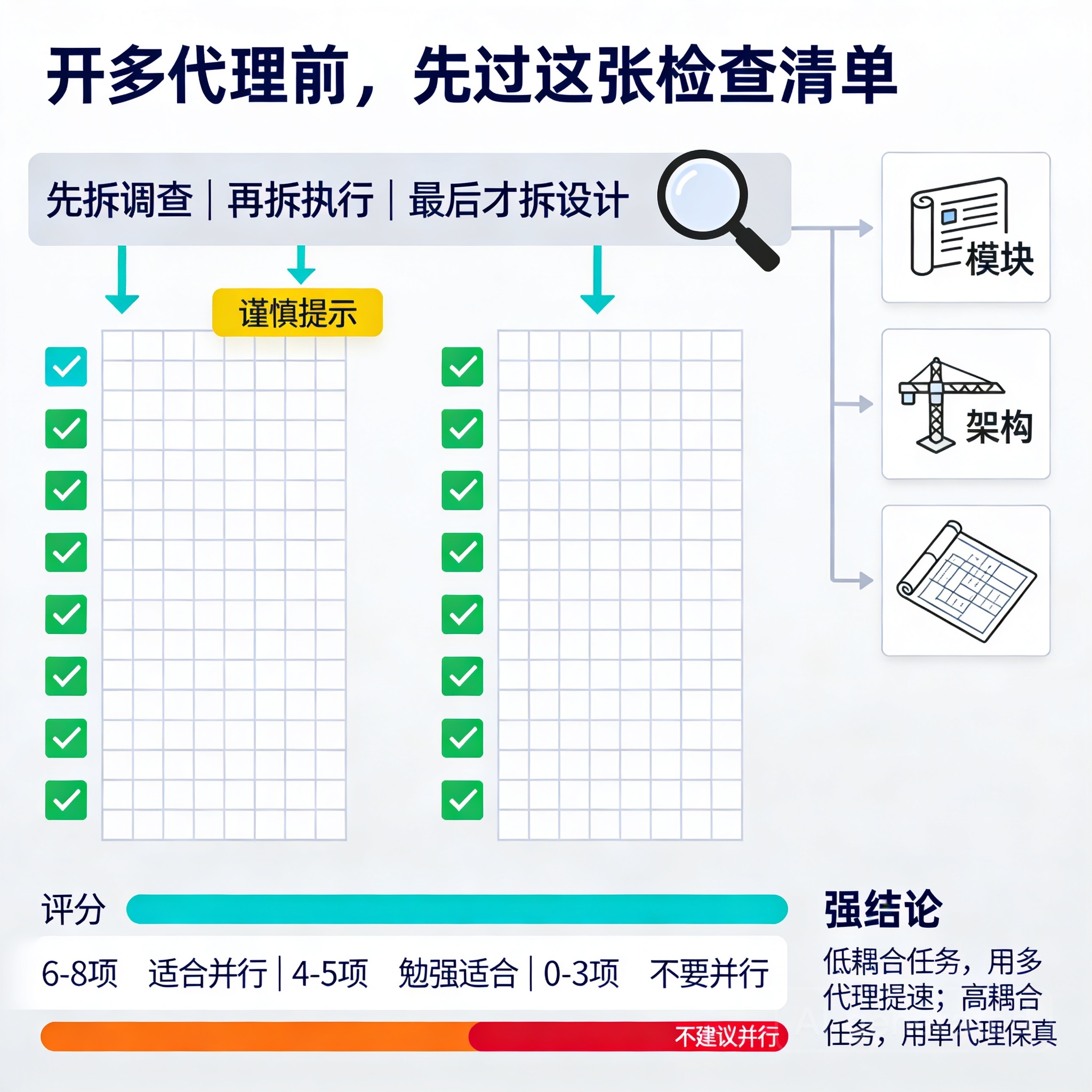
可直接套用的判断清单
开多代理前,快速过一遍这 8 个问题:
- 这个任务能不能切成互不阻塞的子任务?
- 每个子任务是否只需要局部上下文就能完成?
- 子任务之间是否不用频繁共享中间决策?
- 每个子任务是否都有独立、客观的验证方式?
- 某个子任务做错后,回滚是否便宜?
- 我是否已经先定义了统一接口、规范或边界?
- 这次任务的难点是在执行,还是在判断?
- 如果我让三个 agent 同时做,最后冲突最大的会是代码,还是思路?
简单打分法也可以直接用:
- 满足 6-8 项:适合并行
- 满足 4-5 项:勉强适合,先做统一设计再拆
- 满足 0-3 项:不要并行,先单线程收敛问题
最后的判断
Claude Code 多代理最强的地方,不是“一个顶三个”,而是“把不该混在一起的上下文分开”。
所以真正的问题不是“能不能多开 agent”,而是:
这件事到底是在扩展执行带宽,还是在放大认知分叉?
如果是在扩展执行带宽,就并行。
如果是在放大认知分叉,就单线程。
如果是在放大认知分叉,就单线程。
记住这句就够了:
低耦合任务,用多代理提速;高耦合任务,用单代理保真。
低耦合任务,用多代理提速;高耦合任务,用单代理保真。
 Article 4
Article 4Codex Automations 实战:把日报、巡检和周报交给定时代理
基于 OpenAI Academy 与 Codex 官方资料,讨论 Codex 的 Automations 不只是写代码,而是能处理重复性知识工作。文章会从开发者和内容型团队都能理解的角度,讲清哪些任务最适合定时执行,怎样设计输入模板,怎样控制人工复核。
Expand
Article 4
Codex Automations 实战:把日报、巡检和周报交给定时代理
基于 OpenAI Academy 与 Codex 官方资料,讨论 Codex 的 Automations 不只是写代码,而是能处理重复性知识工作。文章会从开发者和内容型团队都能理解的角度,讲清哪些任务最适合定时执行,怎样设计输入模板,怎样控制人工复核。
如果你把 Codex 只当“写代码助手”,其实低估了它最省时间的一面。Codex Automations 的价值,不是多写几个函数,而是把那些“每天都要做、但又不值得人脑反复做”的重复工作,变成按时返回、可复核的结果。
OpenAI Academy 对 Automations 的定义很直接:你不用回来再问一次,Codex 可以在预定时间自己回来、完成任务,并把结果交给你审核。官方也明确给了几个典型方向:reviewing what changed、checking for updates、summarizing recent activity、creating a weekly report。对应到团队日常,最值得先自动化的,恰好就是日报、巡检、周报这类任务。参考:OpenAI Academy Automations 页面 https://openai.com/academy/codex-automations ,以及 Codex 官方文档 Automations 页面 https://developers.openai.com/codex/app/automations 。
这篇只讲一个核心判断:不要先让定时代理做“高风险决策”,先让它接管“高频、低风险、可模板化、输出可检查”的工作。
旧思路为什么低效:不是任务太复杂,而是重复成本太高
很多团队第一次尝试自动化,会想让代理“全权负责”:自动改代码、自动发周报、自动清理待办、自动同步多平台。结果通常不是效果惊艳,而是权限太大、边界不清、复核成本更高。
定时代理最适合的,不是替你拍板,而是替你跑流程、整理证据、生成初稿。
一句话总结:能自动化的不是责任本身,而是责任前面的机械劳动。
所以选任务时,我建议只看 4 个条件:
- 高频:每天、每周、每小时重复发生
- 低风险:输出错一点不会直接造成线上事故
- 可模板化:输入结构稳定,提示词能固化
- 输出可检查:人能在 1-5 分钟内完成审核
只要这 4 条里缺两条,就别急着上 Automations。
先搭好框架:一次 automation 至少要写清 5 件事
Codex 官方文档提到,Automations 可以配置 project、prompt、cadence 和 execution environment;在 Git 仓库场景里,还可以选择运行在本地项目或新 worktree。这个点很关键,因为它决定了自动任务是在“只读总结”还是“可能改动代码”的模式下运行。
我建议每个自动任务都固定成下面 5 段:
-
数据范围
看哪些仓库、哪些目录、哪些文档、哪些工单来源。 -
时间范围
例如“过去 24 小时”“本周一到现在”“最近一次成功运行后”。 -
输出格式
必须固定结构,比如摘要、风险、待确认项、原始链接。 -
禁止动作
例如“不允许 merge”“不允许发送外部消息”“不允许删除文件”。 -
人工复核规则
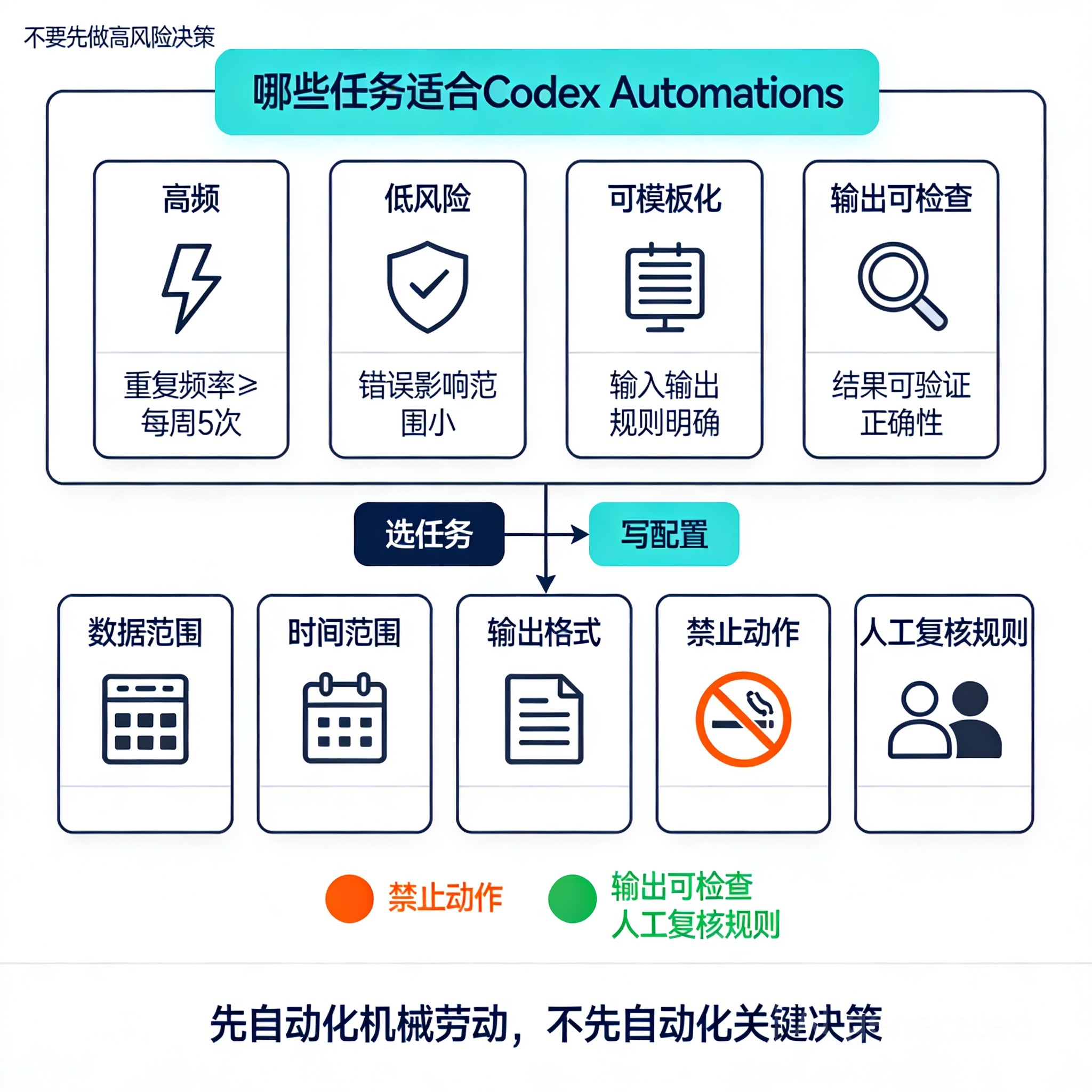
什么情况下直接通过,什么情况下必须人工二次确认。
模板化不是为了让提示词更漂亮,而是为了让失败时能重跑、能定位、能对齐预期。
场景一:代码仓库变更摘要,是开发团队最适合先上的自动化
这是最稳、最容易见效的场景。官方 Academy 页面本身就把“reviewing what changed”作为典型用途,这几乎就是为工程团队的变更摘要量身定做的。
适合什么团队
- 多仓库并行开发
- PR 很多,负责人不可能逐个看完
- Tech Lead 需要早上 5 分钟掌握昨天发生了什么
任务目标
不是让 Codex 判断“代码写得好不好”,而是让它先做一轮结构化归纳:
- 昨天 merged 了哪些 PR
- 涉及哪些模块
- 哪些改动可能影响线上行为
- 是否出现 migration、config、权限、依赖升级
- 哪些 PR 缺测试、缺说明、缺 reviewer follow-up
输入模板怎么设计
可以这样约束:
- 时间范围:过去 24 小时 merged/updated 的 PR 与 commit
- 数据源:指定 GitHub repo 或 monorepo 路径
- 输出结构:
- 3 句话总览
- 模块级变更列表
- 风险项
- 需要人工打开查看的 PR 链接
- 一句建议:今天优先关注什么
关键点是让它“标记风险”,不要让它“决定处理方式”。
人工复核怎么做
审核人只需要重点看三类标签:
- 涉及 schema / migration
- 涉及 auth / payment / config
- 大体量 diff 或无测试改动
这样人审从“自己翻所有记录”变成“只看被标红的部分”。
常见坑
第一,摘要写得像流水账。原因通常是 prompt 没有要求“分级输出”。
第二,漏掉重要风险。原因通常是没有明确要求检查 migration、env、依赖升级。
第三,自动任务直接跑在主工作目录。官方文档提到 Git 仓库可用 dedicated background worktree,涉及代码执行或分析时,优先隔离环境更稳。
第二,漏掉重要风险。原因通常是没有明确要求检查 migration、env、依赖升级。
第三,自动任务直接跑在主工作目录。官方文档提到 Git 仓库可用 dedicated background worktree,涉及代码执行或分析时,优先隔离环境更稳。
场景二:运营/内容周报,是非技术团队最容易理解的用法
很多人看到 Codex,会默认它只适合程序员。但 Academy 的案例方向已经明确覆盖 business operations、sales、weekly report 这类知识工作。周报就是最典型的“重复性知识整理”。
适合什么团队
- 内容团队每周都要汇总选题、发布、数据、反馈
- 运营团队要整合多个来源的活动进展
- 创始人或负责人需要先看到“第一版周报”
任务目标
自动生成“可改的初稿”,而不是“一键发送的终稿”。
一个好周报至少应该包含:
- 本周完成事项
- 关键数据变化
- 表现最好/最差的内容或活动
- 风险与阻塞
- 下周建议动作
输入模板怎么设计
周报场景最怕“资料源不统一”。所以输入一定要先标准化,至少指定:
- 数据源清单:文档、表格、项目管理工具、内容库
- 时间范围:本周一 00:00 到当前
- 口径说明:曝光、点击、转化、发布数按哪个系统为准
- 输出风格:面向老板、面向团队、面向跨部门
一个实用模板是:
“读取本周内容发布记录、表现数据与项目备注。输出 600-800 字周报草稿,分为:本周结果、关键动作、异常点、下周计划、需要决策。若数据冲突,列出冲突项,不要自行猜测。”
注意最后一句非常重要:不要猜。
人工复核怎么做
复核顺序建议固定为:
- 先看数字是否错
- 再看结论是否过度推断
- 最后改语气与措辞
不要反过来。很多团队花最多时间改文字,却没先查口径,结果周报读起来很顺,数字却错。
常见坑
- 多来源数据口径不一致,代理会“合理化补全”
- 输出太长,像复读数据
- 把“事实摘要”和“行动建议”混在一起
解决方法很简单:把输出拆成“事实层”和“判断层”,并要求每条判断尽量对应原始依据。
场景三:待办巡检,适合所有被“积压任务”困扰的团队
这是我最推荐的第三类。因为它不 glamorous,但很有用。OpenAI Academy 提到的 checking for updates,本质上就可以落到待办巡检:哪些事项卡住了,哪些没人认领,哪些截止时间快到了。
适合什么团队
- 用 Notion、Jira、Linear、Trello 管任务
- 经常出现“这个事是不是没人跟了”
- 负责人每天要花时间问进度
任务目标
让 Codex 自动识别异常,而不是自动修改任务状态。
巡检结果只要回答 4 个问题就够了:
- 哪些任务超过 SLA 或截止时间
- 哪些任务没有 owner
- 哪些任务长时间无更新
- 哪些任务状态与最近评论不一致
输入模板怎么设计
一个可落地的提示结构:
“检查指定项目中的开放任务。找出无 owner、逾期、7 天无更新、状态与评论冲突的条目。输出异常清单,每条包含:任务标题、链接、异常原因、建议下一步。不要自动修改系统状态,不要关闭任务。”
你会发现,好的自动化提示词里,限制语句和动作边界,往往比任务描述更重要。
人工复核怎么做
巡检类任务的审批门槛应该非常低:
- 代理可以整理和排序
- 人来确认是否催办、改优先级、重新分配
也就是说,自动化负责“发现问题”,管理者负责“处理问题”。
常见坑

- 任务系统字段命名混乱,导致巡检误判
- “无更新”不等于“无进展”,可能实际在别处沟通
- 过于频繁提醒,反而制造噪音
所以频率建议从每周一次或每天一次开始,不要一上来每小时巡检全量任务。
真正决定成败的,不是模型,而是审批链
很多人把自动化失败归因于模型不够强,其实更常见的问题是流程设计太松。
我建议把 Codex Automations 分成 3 个层级:
第 1 级:只读摘要
只收集、总结、分类。最适合先上线。
只收集、总结、分类。最适合先上线。
第 2 级:生成草稿
可以写周报、建议清单、排查说明,但不直接发布。
可以写周报、建议清单、排查说明,但不直接发布。
第 3 级:执行动作
例如提交 PR、触发外部系统更新、发送消息。这一级必须附带审批或严格 guardrails。
例如提交 PR、触发外部系统更新、发送消息。这一级必须附带审批或严格 guardrails。
如果你的团队还没建立稳定的人审流程,就不要直接跳到第 3 级。自动化最怕的不是“偶尔失败”,而是“悄悄做错还没人看”。
失败重跑要怎么设计
自动任务不是一次写好就永远稳定。真正可用的自动化,一定支持失败后快速重跑。
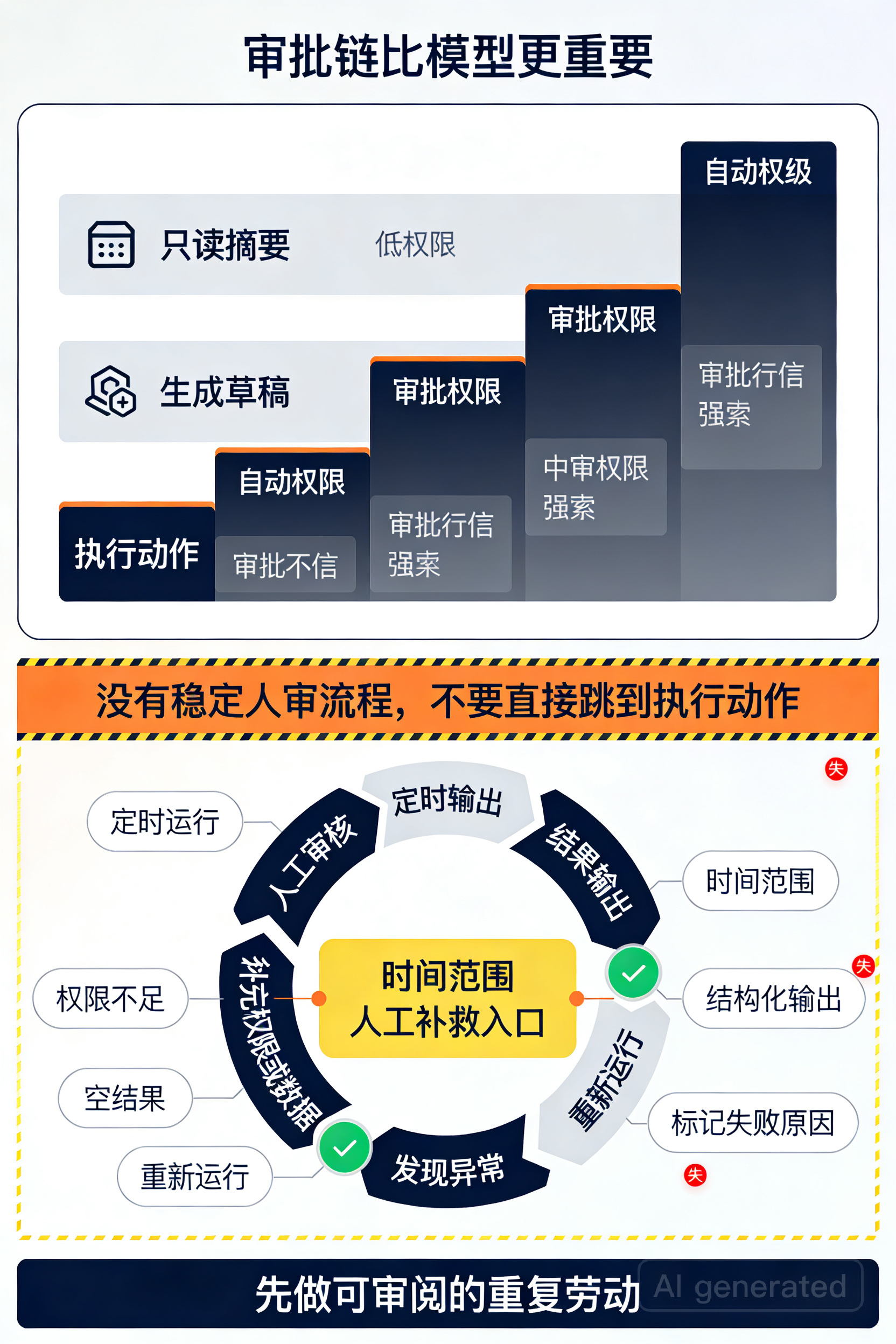
建议至少做到这几点:
- 每次输出都带时间范围,避免重复统计
- 固定结果结构,方便对比前后两次差异
- 对外部数据源超时、权限不足、空结果单独标记
- 失败时返回“缺什么”,而不是只说失败
- 保留人工补救入口,不让流程卡死
一个很实用的原则是:把失败结果也做成可读报告。这样你不是在 debug 黑盒,而是在修一个可观察的流程。
结论:先自动化“可审阅的重复劳动”,不要先自动化“不可逆的决策”
Codex Automations 值得用,但最值得自动化的,不是最炫的任务,而是最无聊、最重复、最容易检查的任务。
如果你现在准备落地,我建议顺序就是这三个:
- 代码仓库变更摘要
- 运营/内容周报初稿
- 待办异常巡检
它们共同满足 4 个条件:高频、低风险、可模板化、输出可检查。这样的任务最容易做出正反馈,也最容易让团队建立对代理的正确预期。
最后给一个判断标准:如果一个任务的最好结果是“帮你少花 30 分钟整理信息”,它很适合自动化;如果一个任务的最坏结果是“替你做错关键决定”,那就先别交出去。
自动化不是为了取消人工,而是把人工留给真正需要判断的地方。
 Article 5
Article 5Claude Code vs Codex:不是谁更强,而是谁更适合你的代码库治理方式
常见对比文章只比生成效果,这篇换一个更实用的角度:比较 Claude Code 与 Codex 在项目记忆、团队约束、自动化、审批机制、长任务连续性上的差异,帮助开发者判断该怎么选,而不是追求一句“谁赢了”。
Expand
Article 5
Claude Code vs Codex:不是谁更强,而是谁更适合你的代码库治理方式
常见对比文章只比生成效果,这篇换一个更实用的角度:比较 Claude Code 与 Codex 在项目记忆、团队约束、自动化、审批机制、长任务连续性上的差异,帮助开发者判断该怎么选,而不是追求一句“谁赢了”。
Claude Code vs Codex:不是谁更强,而是谁更适合你的代码库治理方式
如果你在团队里推进 AI 编程,最容易问错的问题就是:“Claude Code 和 Codex 谁更强?”
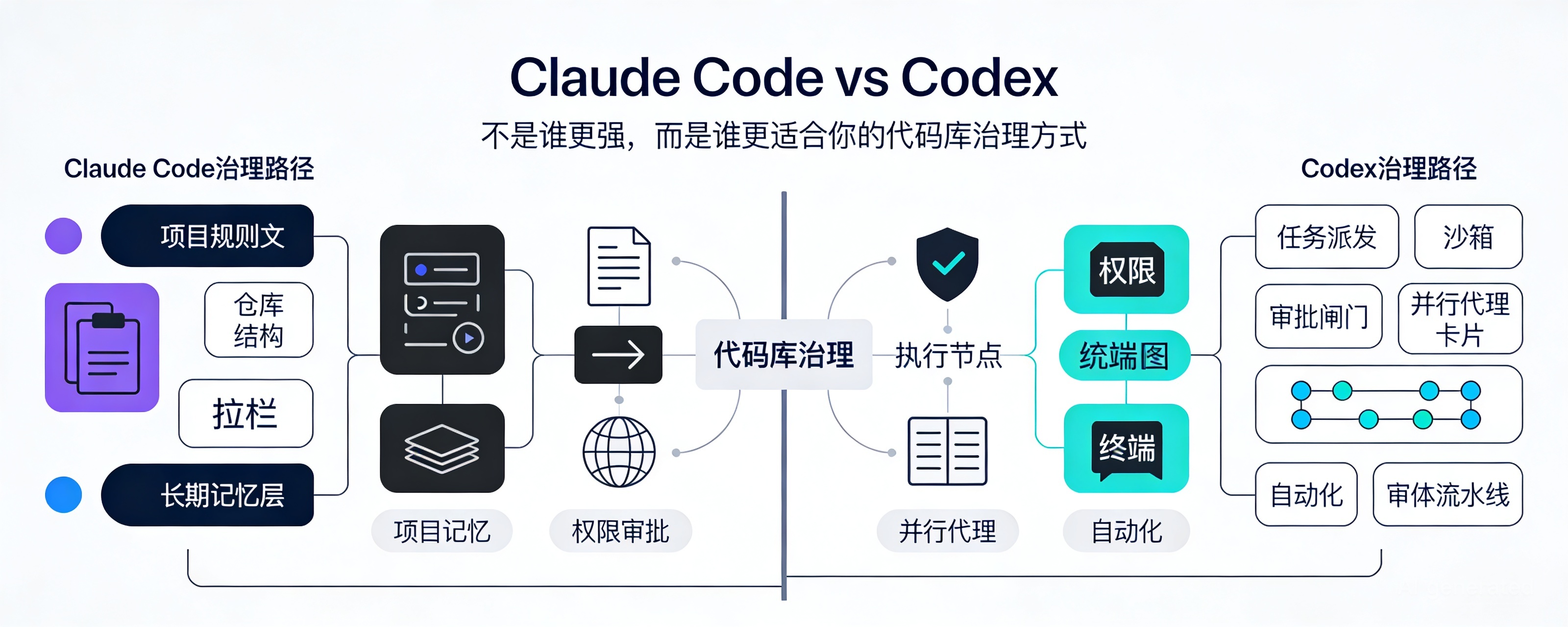
更实用的问题其实是:你的代码库,到底需要一种“对话式协作治理”,还是一种“任务派发式治理”。前者决定 AI 如何长期遵守项目约束,后者决定 AI 如何被审批、并行、审计、接入自动化。选错了,不是生成效果差一点,而是团队根本推不动。
先给结论:Claude Code 和 Codex 都不只是“会写代码”的模型壳,它们都在往“可治理的编码代理”走。但两者的治理重心不一样。Claude Code 更像把规则沉到项目上下文和执行流程里,让 AI 在本地协作中逐步学会你的仓库;Codex 更像把任务拆出去,让 AI 在沙箱里并行执行、审批回收、自动化接管。你该选的不是赢家,而是更贴合你团队控制面的那一个。
旧的比较方法,为什么会误导
只比一段 prompt 下谁改出的代码更好,看起来直观,实际上对团队价值很小。
因为真实开发里,决定 AI 是否可用的,往往不是单次生成质量,而是这 6 个问题:
- 它怎么记住项目规则
- 它能不能接入自动化流程
- 哪些动作需要审批,审批粒度够不够
- 能不能把复杂任务拆成并行代理
- 长任务能不能持续推进并留下可审计痕迹
- 新人要花多久学会把它“管住”
这也是本文的主线:把比较对象从“模型能力”切换成“代码库治理方式”。
一句话看懂两者的治理哲学
Claude Code 官方文档把项目记忆明确落在
https://docs.anthropic.com/en/docs/claude-code/memory
https://docs.anthropic.com/en/docs/claude-code/hooks-guide
https://docs.anthropic.com/en/docs/claude-code/sub-agents
CLAUDE.md 上,并区分了 managed policy、用户级、项目级等不同作用域;同时还有 hooks、skills、subagents 这套机制,把规则、工具和分工嵌进日常开发流里。官方文档:https://docs.anthropic.com/en/docs/claude-code/memory
https://docs.anthropic.com/en/docs/claude-code/hooks-guide
https://docs.anthropic.com/en/docs/claude-code/sub-agents
Codex 官方文档则把项目说明集中在
https://developers.openai.com/codex/guides/agents-md
https://developers.openai.com/codex/app/automations
https://developers.openai.com/codex/agent-approvals-security
https://developers.openai.com/codex/subagents
AGENTS.md,并强调 automations、agent approvals、安全边界、subagents、云端/本地多表面协同。它更像一个可派工、可审批、可并发的工程代理系统。官方文档:https://developers.openai.com/codex/guides/agents-md
https://developers.openai.com/codex/app/automations
https://developers.openai.com/codex/agent-approvals-security
https://developers.openai.com/codex/subagents
可以把它们粗略理解成:
- Claude Code:先把“仓库规矩”写深,再让代理在规矩里工作
- Codex:先把“任务流转”搭好,再让代理在边界里执行
维度一:项目记忆文件,不只是记事本,而是治理入口
这部分是最容易被低估的。
Claude Code 使用
CLAUDE.md。官方文档明确区分:- 组织级 managed policy
- 用户级
~/.claude/CLAUDE.md - 项目级
./CLAUDE.md或./.claude/CLAUDE.md
这意味着它天然适合把“长期规则”分层管理:公司安全规范放系统层,个人习惯放用户层,仓库架构约束放项目层。对于多人协作仓库,这个分层非常关键,因为你不需要把所有规则都塞进一个文件里,更适合持续演进。
Codex 使用
AGENTS.md。它的官方定位很直接:把它当成“给 AI coding agents 的 README”。它也支持在子目录放嵌套的 AGENTS.md,适合 monorepo 或多子项目分区治理。这个设计对大型仓库也很好用,但它更偏“把代理需要知道的事明确写给它”,强调任务执行前的上下文注入,而不是 Claude Code 那种“规则层级 + 长期协作记忆”的味道。如果你的团队更重视:
- 架构约束持续沉淀
- 项目规则分层管理
- 个人/团队/组织三层共存
Claude Code 的
CLAUDE.md 体系更顺手。如果你的团队更重视:
- 给代理快速交底
- 不同目录独立说明
- 面向任务交接而不是长期陪跑
Codex 的
AGENTS.md 更直接。一句话总结:
CLAUDE.md 更像“仓库宪法”,AGENTS.md 更像“代理施工手册”。维度二:自动化能力,谁更像被你接进流水线
Claude Code 的自动化主力是 hooks、skills、Agent SDK、MCP。官方 hooks 文档里已经明确支持自动化项目规则、阻止危险编辑、自动批准特定权限提示、审计配置变化等。这很适合把 AI 行为嵌进本地开发和团队规范里,比如:
- 改动敏感目录前先拦截
- 生成代码后自动跑格式化/测试
- 根据工具调用类型触发额外检查
它像“开发过程中的智能守门员”。
Codex 的自动化则更偏任务编排。官方文档里有独立的 Automations 页面,且产品页持续强调云端任务、GitHub 连接、后台运行、跨端查看、程序化访问 token。它更适合:
- 定时修复 issue
- 自动做 code review
- 批量处理重复工程任务
- 在云端独立跑长任务并回收结果
它像“可以挂进工程系统里的执行工人”。
所以自动化这件事,两者不是强弱,而是接入位置不同:
- Claude Code:更靠近开发者工作台和仓库本地规则层
- Codex:更靠近任务系统、云执行、审计流转层
维度三:权限与审批,决定团队敢不敢放权
真正影响落地的不是 AI 能做什么,而是你敢让它做多少。
Claude Code 的官方文档把 settings、managed settings、MCP allowlist、managed hooks only 等控制项写得很细,企业或 IT 可以通过 managed settings 统一限制可用 MCP、hook 来源和策略行为。再加上 hooks 可以对工具调用做条件判断,它很适合“在本地协作里细粒度收权”。
Codex 则把 approvals 和 sandbox 边界放在更靠前的位置。官方页面强调默认在沙箱里运行,网络默认关闭,并有 agent approvals & security、auto-review mode 等机制,适合把“哪些操作越过边界、谁来批、怎么留痕”做成显式流程。
这会导向两种不同治理感受:
- Claude Code:像在你的仓库里装很多护栏
- Codex:像把代理放进可控施工区,出区前必须过闸机
如果你团队敏感的是“本地仓库里别乱动、规则必须内嵌”,Claude Code 更合适。
如果你团队敏感的是“执行环境必须隔离、每次越权都要可审计”,Codex 更合适。
如果你团队敏感的是“执行环境必须隔离、每次越权都要可审计”,Codex 更合适。
维度四:并行代理,不是谁能并行,而是谁更适合拆活
Claude Code 官方有 subagents,也支持 agent teams、隔离上下文、不同工具限制。它的优势在于:你可以围绕仓库长期定义一组角色,例如 reviewer、refactorer、test-writer,让主代理在项目语境里委派工作。它适合“围绕同一仓库长期形成分工”。
Codex 官方也有 subagents,而且产品实践里一直强调 parallel tasks、后台任务、不同 surface 协同。它更适合把大任务拆成多个独立执行单元,比如:
- 一个代理定位问题
- 一个代理写修复
- 一个代理补测试
- 一个代理做 code review
然后你统一审批和回收结果。
区别在于:
- Claude Code 的并行,更像“同一个团队在同一工地协作”
- Codex 的并行,更像“项目经理同时外包多个工单”
前者适合深上下文、强协作;后者适合高吞吐、强编排。
维度五:适合的任务类型,其实已经暴露了治理倾向
如果你的任务是这些:
- 在老仓库里持续重构
- 逐步沉淀团队代码规范
- 边写边解释边修正
- 需要紧贴本地环境、命令、目录结构协作
Claude Code 往往更顺。因为它的强项是把“项目记忆 + 规则约束 + 本地工作流”做成连续体验。
如果你的任务是这些:
- 批量 issue 处理
- 云端长时间运行
- PR 级别的异步交付
- 自动 review、自动修补、自动排队执行
- 需要更明确的审批链和执行证据
Codex 往往更顺。因为它的强项是把“任务代理化”,而不只是把“对话变强”。
别再问谁更适合“写代码”。真正该问的是:你是想培养一个懂仓库规矩的搭档,还是调度一组可审批的执行代理。
维度六:学习成本,表面差不多,实则学习对象不同
Claude Code 的学习成本主要在“怎么把仓库规则写进系统”。你需要理解
CLAUDE.md 分层、hooks、skills、subagents、managed settings。它难的地方不是命令,而是治理设计:哪些规则该进项目,哪些该进组织,哪些该做 hook,哪些只该写成建议。Codex 的学习成本主要在“怎么把任务系统化”。你需要理解
AGENTS.md、automations、approvals、安全边界、subagents、云端/本地执行差异。它难的地方也不是调用,而是流程设计:哪些任务适合异步派发,哪些审批可以自动化,哪些必须人工兜底。所以两者学习曲线并不等价:
- Claude Code 学的是“如何把 AI 纳入仓库规范”
- Codex 学的是“如何把 AI 纳入工程流程”
我的判断:按治理方式选,不按热度选
如果你是个人开发者或小团队,核心诉求是“让 AI 越来越懂这个项目”,优先看 Claude Code。
如果你是平台团队、工程效率团队,核心诉求是“让 AI 成为可调度、可审计、可并行的执行层”,优先看 Codex。
如果你们是中大型团队,最现实的做法甚至不是二选一,而是分层使用:本地深协作用 Claude Code,异步工单和自动化流水线用 Codex。
如果你是平台团队、工程效率团队,核心诉求是“让 AI 成为可调度、可审计、可并行的执行层”,优先看 Codex。
如果你们是中大型团队,最现实的做法甚至不是二选一,而是分层使用:本地深协作用 Claude Code,异步工单和自动化流水线用 Codex。
最后给你一张适合转发收藏的决策表。
决策表:按代码库治理方式选 Claude Code 还是 Codex
| 比较维度 | Claude Code | Codex | 更适合谁 |
|---|---|---|---|
| 项目记忆文件 | CLAUDE.md,支持组织/用户/项目分层记忆与规则管理 | AGENTS.md,像给代理的 README,支持目录级嵌套说明 | 需要分层治理选 Claude Code;需要快速交底选 Codex |
| 自动化能力 | hooks、skills、MCP、Agent SDK,偏本地流程内嵌自动化 | automations、云端任务、GitHub 集成、后台运行,偏任务编排 | 想把 AI 嵌进开发过程选 Claude Code;想把 AI 接进流水线选 Codex |
| 权限/审批 | managed settings、MCP allowlist、hooks 控制,偏仓库内护栏 | sandbox、approvals、安全边界、auto-review,偏执行边界控制 | 规则内嵌治理选 Claude Code;审批流治理选 Codex |
| 并行代理 | subagents/agent teams,适合同仓库深上下文协作 | subagents/parallel tasks,适合多工单并发执行 | 深协作选 Claude Code;高吞吐选 Codex |
| 适合任务类型 | 重构、解释、局部迭代、长期陪跑式开发 | issue 处理、PR 生成、异步修复、批量工程任务 | 日常主力搭档选 Claude Code;异步执行代理选 Codex |
| 长任务连续性 | 更强调项目上下文连续性与规则继承 | 更强调后台运行、跨端查看、任务回收与审计 | 本地连续协作选 Claude Code;远程长任务选 Codex |
| 学习成本 | 学“如何写规则、控上下文、管仓库” | 学“如何拆任务、配审批、做自动化” | 偏开发规范建设选 Claude Code;偏工程平台建设选 Codex |
结尾只留一句判断:AI 编程工具的分水岭,从来不是“能不能写代码”,而是“你能不能把它纳入治理”。谁更适合你,不取决于榜单,而取决于你的代码库到底需要一个搭档,还是一个执行系统。
 Article 6
Article 6华为发布韬定律
Expand
Article 6
华为发布韬定律
如果你只把“韬定律”理解成华为给半导体起了一个新概念,那大概率会看偏。
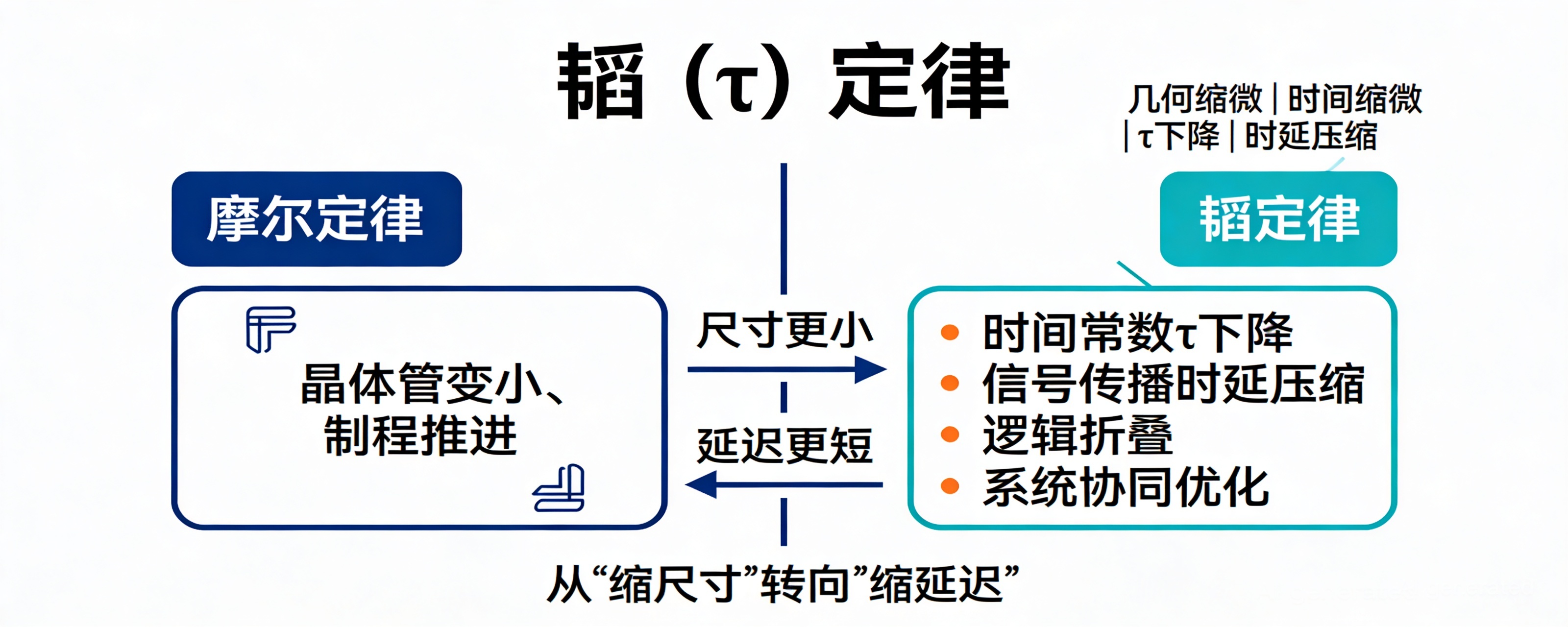
这次最值得关注的,不是一个传播层面的口号,而是华为公开给出了一条不同于传统“拼制程、拼几何缩微”的芯片演进思路:当摩尔定律越来越接近物理和经济极限,性能提升不再只能靠“把晶体管做得更小”,还可以靠“把时间常数做得更短”。
这件事为什么值得看?因为它直接回答了一个现实问题:在先进制程越来越难、越来越贵的背景下,芯片还能靠什么继续进化。
先说结论:韬定律是在回答“后摩尔时代怎么继续提性能”
根据 2026 年 5 月 25 日公开报道,华为公司董事、半导体业务部总裁何庭波在国际电路与系统研讨会上正式发表“韬(τ)定律”。公开表述里最核心的一句是:
“以时间缩微替代几何缩微,以系统性降低时间常数(τ)为目标,通过逻辑折叠等创新技术,持续压缩信号传播时延,不断提升晶体管密度,实现半导体与电子系统的持续演进。”
这段话不短,但可以压缩成一句人话:
过去主要靠“缩尺寸”,现在开始强调“缩延迟”。
这不是说几何缩微不重要了,而是说当几何缩微越来越难时,系统、架构、电路、封装和互连这些层面,开始从“配角”变成“主路径”。
公开资料还提到两个很强的信号:
一是华为称,过去六年已成功设计并量产 381 款芯片;
二是预计到 2031 年,基于该定律的高端芯片晶体管密度将达到 1.4 纳米制程的同等水平。
这两个信息放在一起看,意思很明确:华为不是在讲纯理论,而是在尝试把这套方法论落到产品和产业路径上。
为什么旧思路开始不够用了:问题不只是“制程难”,而是“收益变差”
很多人理解半导体进步,停留在一个朴素公式:制程越先进,芯片越强。
这个公式过去大体成立,但现在越来越不完整。
原因有三点。
第一,物理极限越来越近。
晶体管继续微缩,漏电、发热、制造复杂度、良率问题都会变得更尖锐。
第二,经济账越来越难算。
先进制程不是不能做,而是做出来的成本、设备、工艺门槛和供应链要求都极高。性能提升还在,但边际收益没以前那么漂亮。
第三,系统瓶颈越来越突出。
今天很多高性能计算问题,卡住的未必只是晶体管本身,更多是数据搬运、访存延迟、片上互连、封装带宽、能耗和热设计。你把某个单点做强,不一定能换来整机体验的同比例提升。
所以,“只盯制程”这条路没有失效,但已经不够解释未来十年的主战场。
新框架是什么:从“面积竞争”转向“时间竞争”
“韬(τ)定律”里最关键的符号就是 τ,也就是时间常数。
对技术读者来说,这个概念并不陌生。系统响应快不快、信号传播慢不慢、数据在模块之间移动有没有额外损耗,本质上都和时间常数、延迟链路、互连效率相关。
所以,华为这次给出的新框架,可以理解为四层变化:

第一层,不再只把优化目标放在晶体管尺寸上,而是放在“整体时延”上。
第二层,不再只优化单个器件,而是器件、电路、芯片、系统协同优化。
第三层,不再只追求局部性能峰值,而是追求全栈演进效率。
第四层,用逻辑折叠等技术路线,换取更高密度和更短路径。
这里最值得注意的是“逻辑折叠”。
从公开表述看,它是这条路线里的关键技术抓手。虽然目前公开信息还不够细到论文级别,外界还无法完整验证其具体实现细节,但从名字和语义判断,它强调的是通过结构重组、路径压缩、层次优化来减少信号传播时延,而不是单纯依赖线性平面扩展。
换句话说,它更像是在重新设计“逻辑怎么摆、信号怎么走、系统怎么协同”。
这件事对技术人意味着什么:芯片优化会更像“系统工程”
如果你是做 AI、做系统、做硬件、做端侧设备的人,这条消息真正值得关注的地方,不是“华为提出了一个新定律”,而是下面这个趋势:
未来芯片竞争,越来越像系统工程竞争。
以前大家习惯按层理解:
材料是材料,器件是器件,电路是电路,系统是系统。
但从这次“韬定律”的表达来看,未来真正拉开差距的,可能恰恰是跨层协同能力。谁能把器件、电路、架构、封装、软件调度、系统通信一起优化,谁就更有机会在后摩尔时代跑出来。
这和 AI 领域其实很像。
今天做大模型,也不是只看模型参数本身,而是看训练系统、推理框架、内存带宽、通信开销、部署路径、工程稳定性。单点最强,不等于整体最强。
半导体也越来越进入这个阶段:决定上限的,不只是一个最先进节点,而是一整套组织复杂度的能力。
普通读者最容易误解的 3 个点
1)“韬定律”不是说摩尔定律失效了
更准确的说法是:摩尔定律主导的“几何缩微”收益变慢了,行业需要新的补充路径。
它不是把原来的路线完全推翻,而是在原路线变难之后,提供另一种持续演进的方法论。
2)“达到 1.4 纳米同等水平”不等于“就是 1.4 纳米制程”
公开报道的说法是“晶体管密度将达到 1.4 纳米制程的同等水平”。
这句话必须谨慎理解。
它强调的是“同等水平”的结果对标,不是直接宣称制造工艺节点等同。密度、性能、功耗、良率、成本、生态适配,这些维度不能简单画等号。
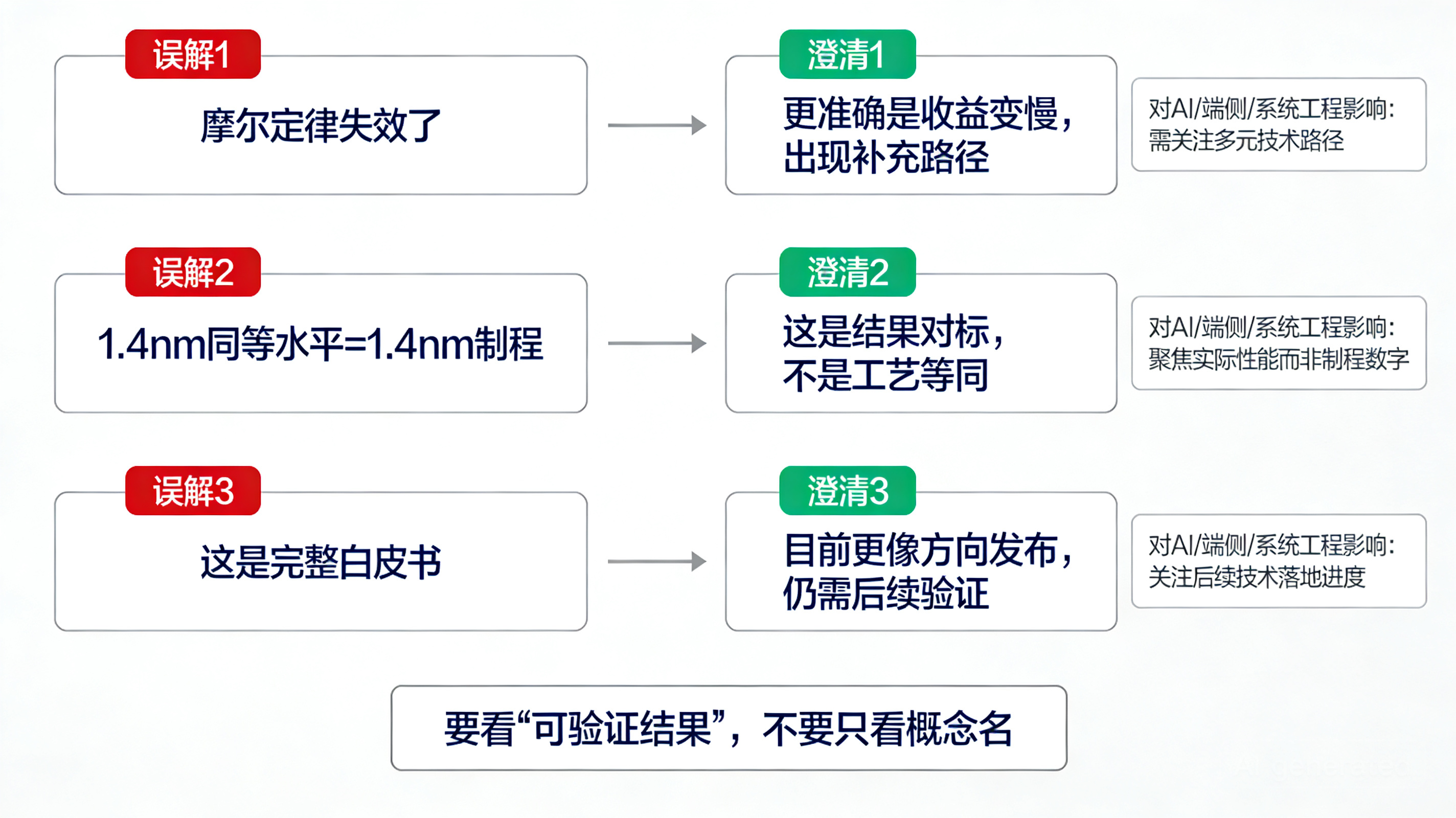
所以这类表述更适合解读成“通过不同技术路径,追求接近先进节点的综合结果”。
3)这更像方向发布,不是完整技术白皮书公开
截至目前,公开资料主要来自新闻报道和会议信息摘要,核心信息已经很清楚,但具体技术实现、评测口径、工艺细节、可复现数据还比较有限。
因此更稳妥的判断是:
这次是一次高层次路线发布,代表方向和产业信号非常强;但要做更深入的技术结论,还需要后续更多论文、产品和量产验证。
为什么 AI 从业者也应该关注这件事
很多人会觉得,这不是半导体新闻吗,和 AI 技术分享有什么关系?
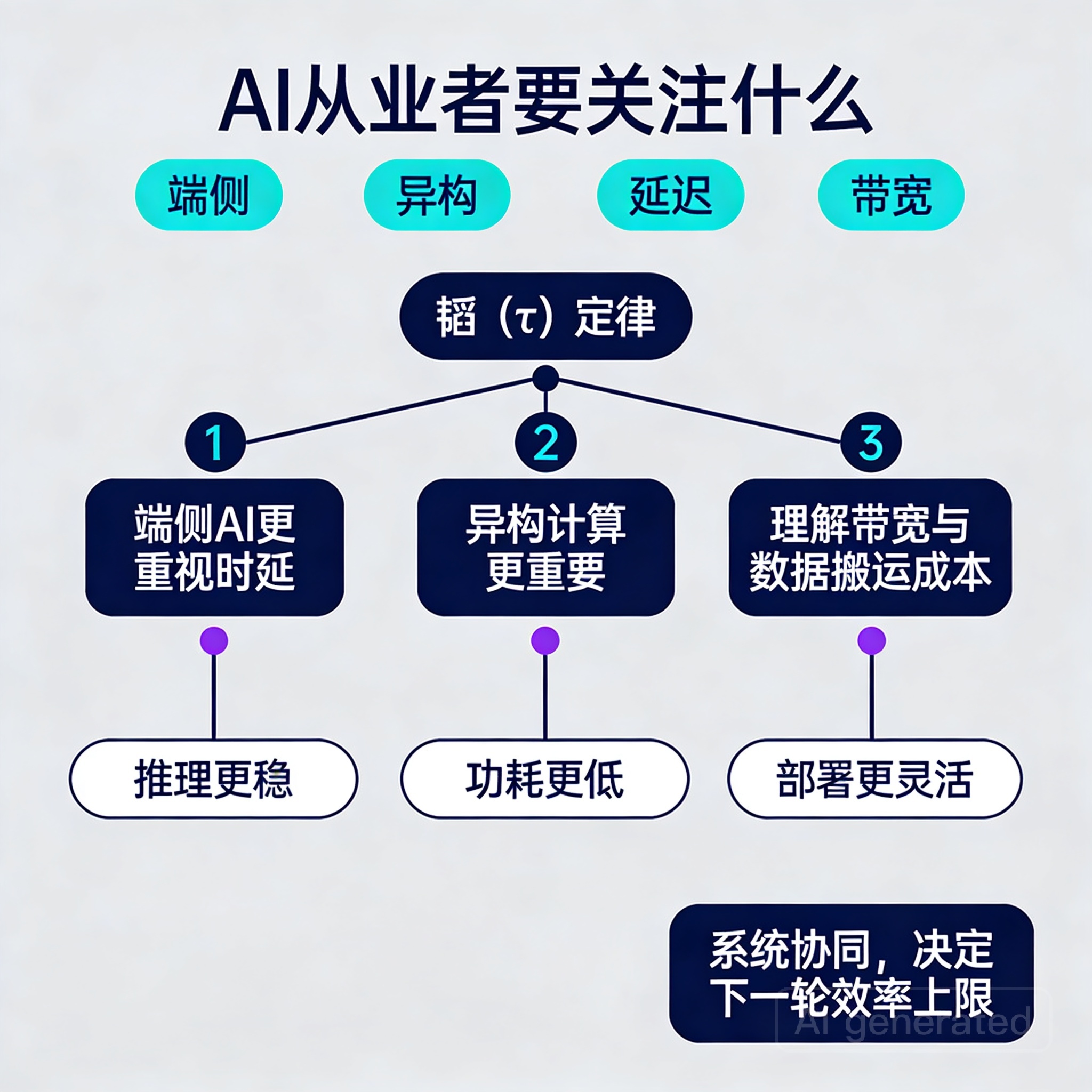
关系非常大。
因为 AI 的上限,越来越受硬件架构限制。训练、推理、端侧部署、低功耗计算、带宽瓶颈、存算效率,这些问题背后都不是单纯的“模型问题”,而是“芯片与系统问题”。
如果“以时间缩微替代几何缩微”这条思路能持续落地,它可能会带来三类影响:
第一,端侧 AI 芯片会更重视时延链路优化,而不是只堆算力参数。
第二,异构计算和系统级协同设计的重要性会进一步上升。
第三,AI 工程师未来需要更理解硬件约束,尤其是数据搬运成本和系统通信成本。
一句话总结就是:
算力竞争的下半场,拼的不是谁喊得更大,而是谁把“延迟、带宽、能耗、系统协同”真正做进产品里。
最后怎么判断这件事的分量
我自己的判断是:这件事的意义,不在于它是否立刻改写整个全球半导体格局,而在于它把一个越来越明确的行业现实说透了——后摩尔时代,芯片演进必须从“单点缩微”转向“全栈协同”。
如果后续华为真能用更多量产产品、公开指标和可验证结果持续支撑这条路线,那“韬定律”就不只是一个命名,而会成为一个值得长期跟踪的技术框架。
对技术人来说,这次发布最值得记住的一句话不是“又一个新定律来了”,而是:
当尺寸越来越难再缩,真正决定未来的,是谁能把时间缩下来。
公开来源可参考:人民网关于 2026 国际电路与系统研讨会报道
http://finance.people.com.cn/n1/2026/0525/c1004-40726802.html
 Article 7
Article 7Codex终极保姆教程:从0到1带你速通
Expand
Article 7
Codex终极保姆教程:从0到1带你速通
Codex终极保姆教程:从 0 到 1,半小时上手 OpenAI 编程代理
如果你把 Codex 还理解成“会补全代码的 AI”,那你大概率会用错它。现在的 Codex 更像一个能在终端里读仓库、改文件、跑命令、做代码审查,甚至接入 MCP 工具的编程代理。
一句话先讲结论:Codex 最适合已经有项目、想把“解释代码、改功能、跑测试、做 review”这类重复工作交给 AI 的人。 它不是拿来替你凭空造系统的,而是拿来把你现有开发流变快 2-5 倍的。
先别急着装:你到底适不适合用 Codex
适合的人群很明确:
- 有本地项目,需要 AI 真正动手改代码
- 经常在终端里工作,希望少切工具
- 想让 AI 帮你做解释、重构、补测试、审查 diff
- 想把 MCP、Web Search、子代理这些能力串进开发流程
如果你只是偶尔问一句“这段代码什么意思”,网页里的 ChatGPT 就够了。Codex 的价值,不在能回答,而在能执行。
3 分钟完成安装和登录
官方入口:
- 产品页:https://openai.com/codex
- 开发文档:https://developers.openai.com/codex/
- CLI 文档:https://developers.openai.com/codex/cli
- GitHub 仓库:https://github.com/openai/codex
Mac / Linux 安装:
curl -fsSL https://chatgpt.com/codex/install.sh | sh
Windows 安装:
powershell -ExecutionPolicy ByPass -c "irm https://chatgpt.com/codex/install.ps1 | iex"
也可以用包管理器:
npm install -g @openai/codex
或:
brew install --cask codex
安装后直接运行:
codex
首次启动会提示登录。官方文档说明,Codex 可用 ChatGPT 账号登录,也支持 API Key。ChatGPT Plus、Pro、Business、Edu、Enterprise 计划都包含 Codex。
第一条正确用法:不要空聊,直接进项目目录
最常见的新手错误,是在一个空目录里打开 Codex,然后问它“帮我做个后台系统”。结果往往很一般。
正确姿势是先进入已有项目:
cd your-project
codex
进入后,先别让它直接写代码,先给它一条探路指令:
先阅读这个仓库,告诉我项目结构、启动方式、关键入口文件和潜在风险,不要修改任何文件。
这样做的好处是,Codex 会先理解上下文。先建模,再动手,成功率会高很多。
半小时速通的 4 个核心动作
1)解释代码库
codex "Explain this codebase to me"
适合刚接手老项目时使用。你也可以让它聚焦某块功能,比如登录、支付、消息队列,而不是泛泛解释整个仓库。
2)直接改功能
进入交互界面后,用自然语言描述需求,例如:
给通知模块加指数退避重试,失败时记录 error code,并补充测试。先说修改计划,再执行。
这里有个关键技巧:永远要求它先给 plan,再执行。 这能显著减少误改。
3)做本地代码审查
Codex CLI 支持
/review。它会启动一个独立 reviewer,读取你选定的 diff,输出优先级更高的问题点,而不直接改你的工作区。/review
这特别适合提交前自查。很多时候,AI review 的价值不是“挑语法毛病”,而是帮你发现遗漏的边界条件。
4)切模型与推理强度
Codex 支持在会话内用
/model 切换模型。官方文档目前提到可在 Codex 中使用 GPT-5.4、GPT-5.3-Codex 等模型,功能页也把 gpt-5.5 作为多数任务的推荐模型。/model
经验上:
- 小改动、快问快答:用更快的模型
- 重构、多文件修改、复杂排查:用更强推理模型
不是所有任务都值得“火力全开”。把最贵的思考,留给最难的问题。
进阶能力:这 3 个功能很容易被低估
Web Search
Codex CLI 自带 Web Search。做 SDK 升级、查最新接口、找官方文档时很有用。要拿更实时的数据,可在单次运行时加
--search,或在配置里设 live 模式。图片输入
你可以给 Codex 传截图、设计稿,让它按视觉稿改前端。
codex -i screenshot.png "根据截图修复这个页面布局问题"
这比纯文字描述 UI bug 高效得多。
MCP 与子代理
如果你的工作流已经接入文档服务、内部 API、设计系统,MCP 能把这些上下文喂给 Codex。子代理则适合复杂任务并行处理,但官方也明确提醒:子代理会消耗更多 token。
新手最容易踩的 5 个坑
- 一上来就让它“从 0 写完整系统”
- 不给约束,导致它乱改文件
- 不先看 plan,直接批准执行
- 在脏工作区里操作,出了问题难回滚
- 把它当搜索引擎,而不是开发代理
我的建议是:每次任务都带上这三个约束——目标、范围、不允许动的部分。例如:
只修改 auth 模块;不要改数据库 schema;改完后运行测试并解释结果。
最后给一个最稳的上手流程
第一次用 Codex,照着这个顺序来:
- 安装并登录
- 进入已有项目目录
- 先让它解释项目,不修改
- 再给一个小需求,只改 1-2 个文件
- 让它补测试
- 最后跑一次
/review
这样走一遍,你基本就能理解 Codex 的真实边界:它不是“自动写代码按钮”,而是“会读、会改、会跑、会审”的开发搭子。
真正会用 Codex 的人,不是把决定权交给 AI,而是把重复劳动交给 AI。 这就是从 0 到 1 上手 Codex 的关键。
 Article 8
Article 8Claude Code 动态工作流
Expand
Article 8
Claude Code 动态工作流
Claude Code 动态工作流:把“单次提问”变成“会自我分工的开发流程”
如果你还把 Claude Code 当成“会写代码的聊天框”,那你大概率只用到了它 30% 的价值。Claude Code 真正强的,不是替你回答一个问题,而是把一次开发任务拆成可持续运行的动态工作流:主任务负责推进,子任务负责清理上下文,记忆负责跨会话复用,Hooks 和 Skills 负责把流程固化。
一句话结论:Claude Code 最适合做的,不是“帮我写这段代码”,而是“帮我持续完成这类任务”。
为什么传统 AI 编程方式会越用越乱
很多人第一次用 AI 写代码,流程通常是这样的:
- 贴报错
- 让模型猜原因
- 让模型改文件
- 再贴新的报错
- 上下文越来越长,结果越来越飘
问题不在模型能力,而在工作方式。单线程对话有三个天然缺陷:
- 搜索、分析、修改、测试全挤在一个上下文里
- 重复任务每次都要重新解释
- 项目规则只存在你脑子里,不存在系统里
所以你会发现,任务越复杂,AI 越像“聪明但健忘的实习生”。
Claude Code 的动态工作流,本质上是在解决这三个问题。
新思路:让 Claude Code 不只是回答,而是分层协作
结合官方文档里的几个核心能力,Claude Code 适合构建这样的四层结构:
- 主会话:负责目标、判断与推进
- Subagents:负责搜索、整理、隔离脏上下文
- CLAUDE.md / Auto memory:负责记住项目规则与常用命令
- Skills / Hooks:负责把高频动作变成稳定流程
官方文档里已经明确支持这些能力:
Claude Code 概览:https://docs.anthropic.com/en/docs/claude-code/overview
常见工作流:https://docs.anthropic.com/en/docs/claude-code/common-workflows
记忆机制:https://docs.anthropic.com/en/docs/claude-code/memory
Subagents:https://docs.anthropic.com/en/docs/claude-code/sub-agents
Hooks:https://docs.anthropic.com/en/docs/claude-code/hooks
Claude Code 概览:https://docs.anthropic.com/en/docs/claude-code/overview
常见工作流:https://docs.anthropic.com/en/docs/claude-code/common-workflows
记忆机制:https://docs.anthropic.com/en/docs/claude-code/memory
Subagents:https://docs.anthropic.com/en/docs/claude-code/sub-agents
Hooks:https://docs.anthropic.com/en/docs/claude-code/hooks
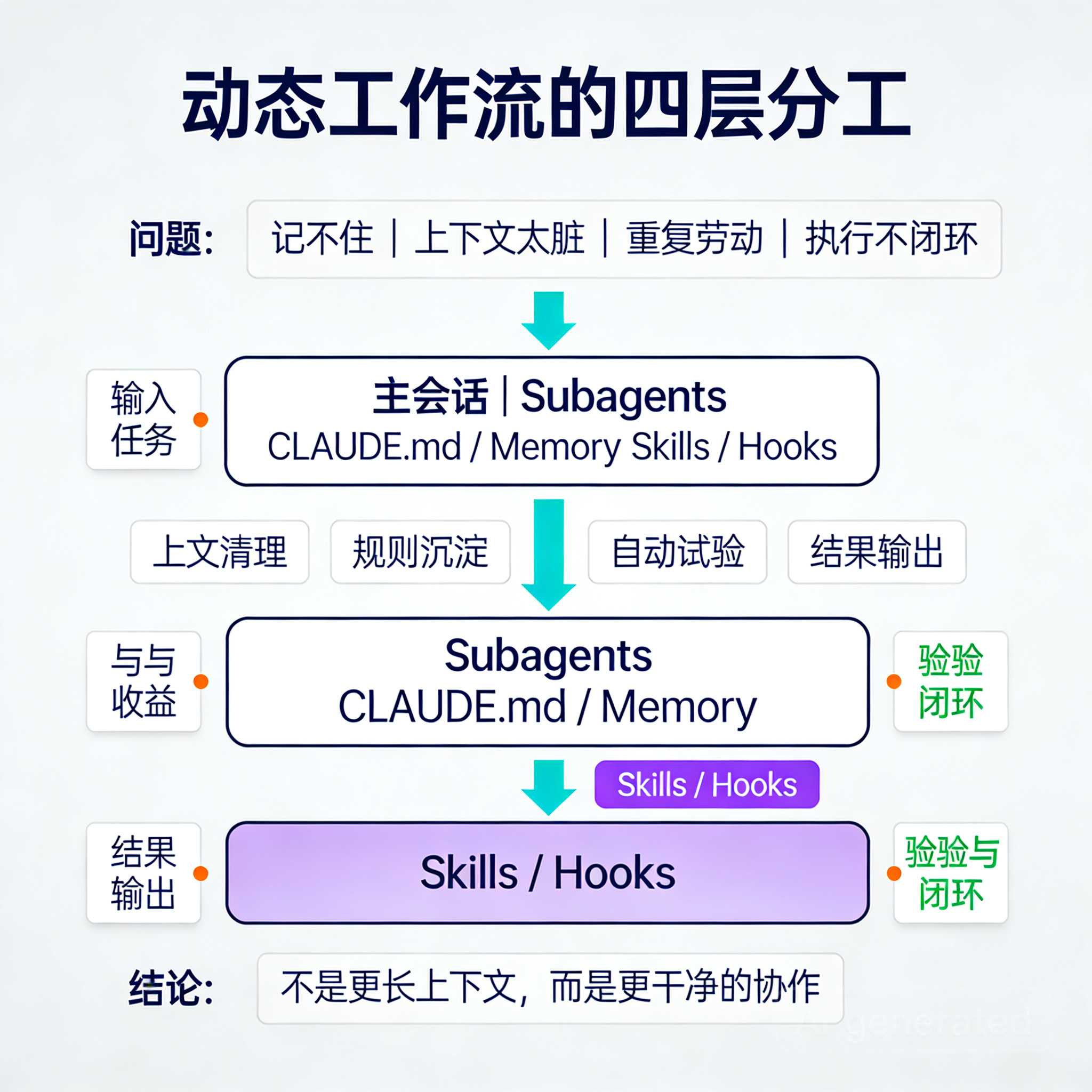
关键理解是:动态工作流不是一个功能,而是这些能力叠加后的使用方式。
一个能直接落地的动态工作流模板
我更推荐把 Claude Code 用成下面这套流程:
1. 先把“长期规则”写进
CLAUDE.md不要每次都口头说“我们项目用 pnpm、提交前跑 lint、组件目录在 src/features”。
把这些写进项目根目录的
把这些写进项目根目录的
CLAUDE.md,让 Claude Code 在每次会话开始时读取。适合写进去的内容:
- 项目结构约定
- 常用启动/测试命令
- 代码风格限制
- 不允许触碰的目录
- 提交前检查清单
这一步的收益非常直接:你不是在重复提示词,而是在建立团队级默认行为。
2. 把脏活交给 Subagent
官方对 subagent 的定位很清楚:当某个侧任务会塞满主上下文时,就让它单独处理,再只返回摘要。
最典型的几个场景:
- 在大仓库里搜认证、支付、埋点相关代码
- 汇总日志、测试输出、错误栈
- 对多个候选修复方案做预分析
- 阅读陌生模块后输出结构摘要
这样主会话不用被几十段日志和文件内容污染。
好工作流的标准不是上下文更长,而是主上下文更干净。
好工作流的标准不是上下文更长,而是主上下文更干净。
3. 把高频动作做成 Skill
如果你经常做这些事:
/review-pr/fix-failing-tests/prepare-release-notes/deploy-staging-checklist
那就别每次重打一遍提示词。Claude Code 官方支持 Skills,用来封装可复用流程。它特别适合团队共享,因为它把“某个人会用 AI”变成“整个团队有标准化 AI 工作法”。
什么时候该做成 Skill?
答案很简单:当一个流程你连续做了三次,还在手动重复,就是该封装的时候。
答案很简单:当一个流程你连续做了三次,还在手动重复,就是该封装的时候。
4. 用 Hooks 把“最后一公里”自动化
Claude Code 的 Hooks 能在特定事件前后触发 shell 命令。这个能力很像给 AI 工作流接上自动化胶水。
最实用的用法不是搞复杂编排,而是处理这些刚需:
- 改完文件后自动格式化
- 执行工具前先做权限检查
- 编辑结束后自动跑 lint
- 会话结束时输出变更摘要
这样可以把“模型生成代码”变成“模型生成 + 自动校验”的闭环。
AI 负责加速,Hook 负责兜底。
AI 负责加速,Hook 负责兜底。
最适合动态工作流的 3 类任务
一是中型重构
比如“把旧工具函数改成现代写法,同时保证行为不变”。
主会话负责制定边界,subagent 负责定位影响面,Hooks 负责触发测试,最后再由主会话汇总结论。
主会话负责制定边界,subagent 负责定位影响面,Hooks 负责触发测试,最后再由主会话汇总结论。
二是 Bug 定位
尤其是“偶发错误 + 多文件联动 + 日志很多”的问题。
这类任务最怕主上下文被错误信息淹没,subagent 非常适合先清洗材料,再交回主线程判断。
这类任务最怕主上下文被错误信息淹没,subagent 非常适合先清洗材料,再交回主线程判断。
三是新成员熟悉代码库
Anthropic 官方也提到团队会用 Claude Code 帮助新人理解代码库。对新人来说,最有价值的不是一次回答,而是一个带记忆、带约束、能持续追问的项目搭子。
3 个常见坑,越早知道越省时间
坑 1:什么都放进主对话
结果是上下文爆炸,后面每一步都变慢、变飘。能分出去的搜索、摘要、日志分析,都尽量分出去。
坑 2:只靠聊天,不写项目记忆
没有
CLAUDE.md,Claude Code 每次都像第一次进组。你以为它“不稳定”,其实是你没给它稳定环境。坑 3:把工作流理解成“全自动”
动态工作流不是放手不管,而是把判断权和执行权拆开。主会话做判断,子任务做搬运,自动化做校验。
真正高效的不是全自动,而是该自动的自动,该人工拍板的人工拍板。
真正高效的不是全自动,而是该自动的自动,该人工拍板的人工拍板。
现在怎么开始,最省力
如果你今天就想试,不要一上来追求复杂 agent 系统。按这个顺序就够了:
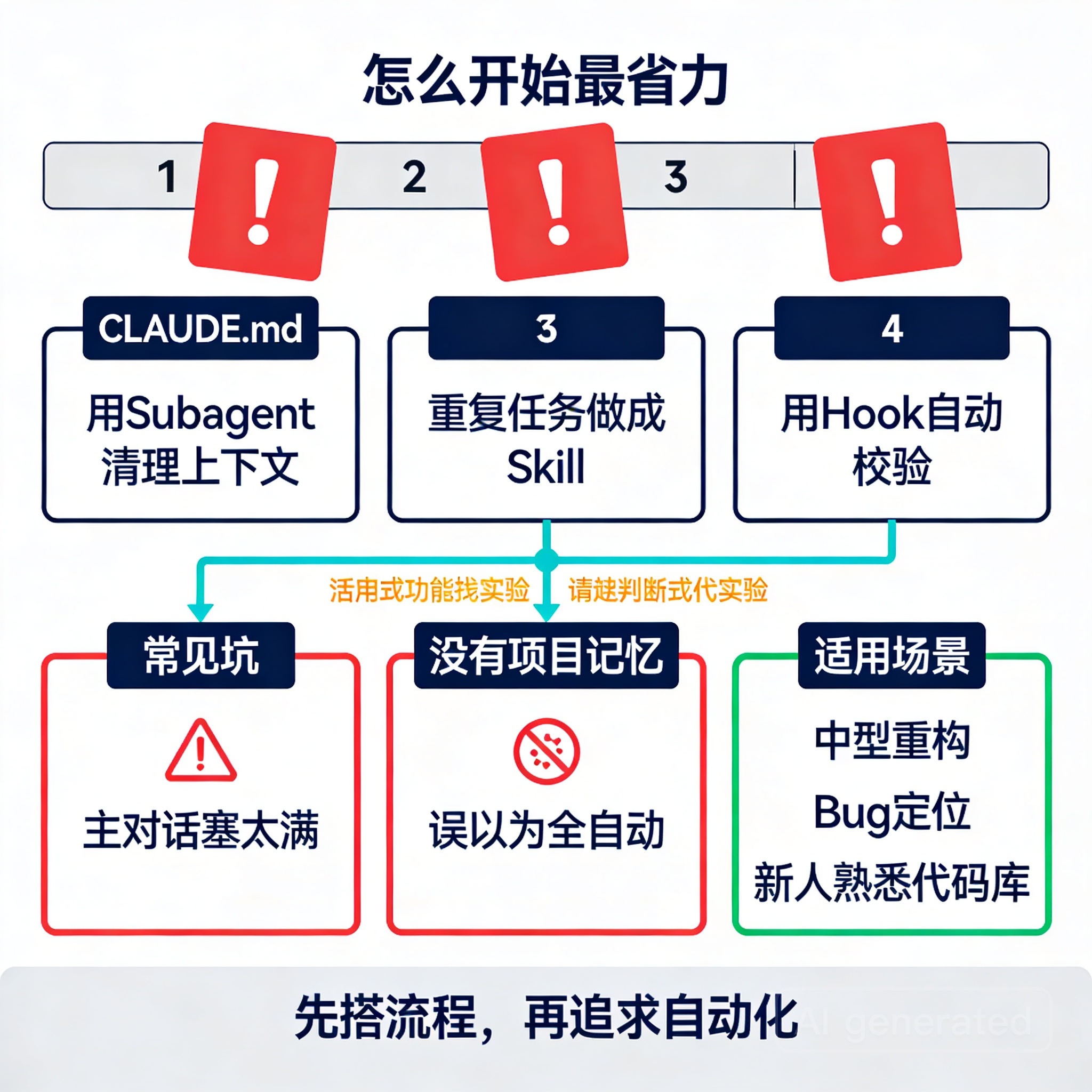
- 在项目里加一个
CLAUDE.md - 选一个重复任务写成 Skill
- 把日志分析或代码搜索交给 subagent
- 加一个最简单的 Hook,比如改完自动 lint
只做这四步,你就已经从“AI 帮我答题”升级成“AI 帮我跑流程”了。
总结
Claude Code 动态工作流的核心,不是更会写 prompt,而是更会设计分工。
CLAUDE.md解决“记不住”- Subagents 解决“上下文太脏”
- Skills 解决“重复劳动”
- Hooks 解决“执行不闭环”
当你把这四件事接起来,Claude Code 才会从一个对话工具,变成一个真正能协作的开发系统。
最后给一个我很认同的判断:
AI 编程的分水岭,不是谁会多问一句,而是谁先把一次提问,升级成一套可复用的工作流。
AI 编程的分水岭,不是谁会多问一句,而是谁先把一次提问,升级成一套可复用的工作流。
 Article 9
Article 9Claude Code 里藏了一套 Skill 系统,90% 的人没打开过
深度拆解 Claude Code 内置的 Skill 机制,从发现、启用、自定义到实战工作流,讲清楚它和普通 prompt 的本质区别及适用场景。
Expand
Article 9
Claude Code 里藏了一套 Skill 系统,90% 的人没打开过
深度拆解 Claude Code 内置的 Skill 机制,从发现、启用、自定义到实战工作流,讲清楚它和普通 prompt 的本质区别及适用场景。
Claude Code 里藏了一套 Skill 系统,90% 的人没打开过
大多数用户把 Claude Code 当成一个“更强的终端 AI”——提问、改代码、提交,循环往复。但 Claude Code 内置的 Skill 系统,才是它从“对话工具”变成“可编程工作流引擎”的真正分界线。
Skill 不是 prompt 模板,不是 alias 快捷指令,而是一种可组合、可复用的能力单元。它定义了 Claude 在特定场景下“如何思考、如何行动、如何输出”。
用了 Skill 之后,你不再是每次从零开始给 Claude 下指令,而是在调教一个已经有了专业肌肉记忆的助手。
什么是 Skill?一句话说清楚
Skill 是 Claude Code 中的结构化能力模块。每个 Skill 包含:
- 触发条件:什么情况下自动激活
- 上下文注入:激活时向 Claude 注入的专业知识、规则、约束
- 工具权限:该 Skill 可以调用哪些工具(文件读写、终端命令、网络请求等)
- 输出格式:期望的返回结构和行为模式
和普通 prompt 的关键区别在于:prompt 是你每次手动输入的一句话,Skill 是一次定义、持续生效、自动激活的系统级配置。
如何发现和启用现有 Skill
Claude Code 默认内置了一批 Skill,但大多数用户从未主动查看过。
在 Claude Code 会话中运行以下命令:
claude skills list
你会看到一个内置 Skill 列表,常见的有:
- code-reviewer:自动审查代码质量、安全漏洞、性能问题
- test-generator:根据代码逻辑自动生成单元测试
- doc-writer:从代码注释和函数签名生成文档
- debugger:分析错误栈、定位根因、给出修复方案
启用一个 Skill 只需一行:
claude skills enable code-reviewer
启用后,当你提交代码或请求审查时,Claude 会自动以审查者视角介入,而不是以通用助手身份回复。
自定义 Skill:把你自己的一套方法论固化下来
内置 Skill 只是起点。真正有价值的是创建自己的 Skill,把你团队的最佳实践、代码规范、审查清单变成可重复执行的能力单元。
创建流程
- 初始化 Skill 目录
claude skills init my-custom-skill
这会在
.claude/skills/my-custom-skill/ 下生成一个 Skill 骨架。- 编辑 Skill 定义文件
打开
skill.yaml,核心字段如下:name: my-custom-skill
description: 按团队规范审查 API 接口设计
triggers:
- keywords: ["api review", "接口审查", "endpoint check"]
- file_patterns: ["**/routes/**", "**/controllers/**"]
context: |
你是一个严格的后端 API 审查者。审查时必须关注:
1. RESTful 命名是否规范
2. 错误码是否统一
3. 请求验证是否完整
4. 响应结构是否符合团队约定
5. 是否存在 N+1 查询风险
tools:
- read
- write
- bash
output:
format: structured
sections:
- severity
- location
- issue
- suggestion
- 加载并测试
claude skills load my-custom-skill
然后直接在对话中说“帮我审查一下这个 API 接口”,Skill 会自动激活并按照你定义的框架输出。
Skill 组合:多个 Skill 串联成工作流
单个 Skill 解决单个环节的问题。当你需要端到端的自动化时,可以把多个 Skill 串联起来。
一个实际场景:代码提交前的“自动关卡”。
claude skills enable code-reviewer
claude skills enable test-generator
claude skills enable my-custom-skill
执行顺序:
my-custom-skill先按团队规范检查接口设计code-reviewer审查代码质量test-generator为新逻辑自动生成测试
整个流程在一次对话中完成,不需要你手动切换上下文。
Skill vs Hook vs Custom Command:三个概念的边界
很多用户把这三者混淆,这里做一个清晰区分:
| 机制 | 触发方式 | 作用范围 | 典型用途 |
|---|---|---|---|
| Skill | 关键词/文件模式自动触发 | 对话上下文+工具权限 | 注入领域知识、改变行为模式 |
| Hook | 事件驱动(pre-commit, post-save) | 系统事件 | 在特定时机自动执行脚本 |
| Custom Command | 用户手动调用 | 单次执行 | 快捷指令、批量操作 |
Skill 的核心优势在于“自动激活+上下文注入”,它改变了 Claude 的思考框架,而不仅仅是执行动作。
一个避坑清单:Skill 用得不对反而降低效率
在实际使用中,以下几个问题最常见:
-
触发条件太宽泛:关键词设成“代码”、“文件”这种高频词,导致 Skill 在不该激活时激活,干扰正常对话。建议用组合关键词或特定文件路径模式。
-
Context 写得太长:一次性注入几千字的规则,会挤占 Claude 的有效上下文窗口,反而影响输出质量。每条 Skill 的 context 控制在 500-800 字以内,只写最关键的约束。
-
不测试边界情况:写完 Skill 就投入使用,结果遇到未覆盖的边缘输入时行为异常。建议用 5-10 个典型用例做激活测试,包括正向和反向案例。
-
重复定义冲突规则:多个 Skill 同时激活时,如果对同一行为有矛盾约束,Claude 的优先级逻辑并不总是符合预期。建议给 Skill 设置优先级(priority 字段),确保冲突时有明确兜底。
总结:Skill 是 Claude Code 的“操作系统层”
如果你只用 Claude Code 做单次问答,Skill 对你可能没那么重要。但一旦你开始把 Claude Code 嵌入团队开发流程,Skill 就是你定义“Claude 应该怎么干活”的唯一标准化手段。
适用人群:任何需要让 Claude Code 在特定场景下表现出稳定、可预期行为的开发者或团队。
下一步建议:先用
claude skills list 看一眼内置 Skill,选一个最贴近你现在痛点的启用试试。等体会到“自动激活”的便利后,再花半小时定义第一个自定义 Skill,把你们团队的一条审码规范固化进去。把方法论变成 Skill,就是把“我说你听”变成“你自带专业本能”。这才是 Claude Code 的正确打开方式。
 Article 10
Article 10CLIProxyAPI: 自建API中转服务
Expand
Article 10
CLIProxyAPI: 自建API中转服务
CLIProxyAPI实战:自建API中转服务,告别第三方API中转依赖
如果你同时订阅了Claude Code、OpenAI Codex、Gemini,可能还接入了Antigravity等工具,那你一定经历过这样的痛苦:
Claude Code只能用Claude,Gemini CLI只能用Gemini。想在Claude Code里调用其他模型?不行。想多个账户轮流用?手动切换。一个号配额满了?自己换。更麻烦的是,如果你的SaaS业务需要稳定调用文本模型和生图模型,通常还得额外依赖市面上的API中转服务。
CLIProxyAPI解决的就是这个问题:一个本地或服务器代理地址,接管所有AI账户,自动轮询、自动切换、自动转换格式。程序只有10MB,内存占用不到10MB,改配置不用重启,开源免费。
我实际接入了Codex和Antigravity,已经跑通了文本模型和生图模型,并直接提供给自己的SaaS业务使用。接入后,完全不再需要使用市面上的API中转服务了。
为什么你需要CLIProxyAPI?
AI编程工具越来越多,但每个工具都有自己的生态壁垒。Claude Code、Cursor、Cline、Roo Code、Continue、Trae……每个工具都要求你使用特定的API或订阅。
更糟糕的是,这些工具的配额管理各不相同。Claude Code有小时限制,Codex有5小时/周配额,Gemini有请求频率限制。当你同时使用多个工具时,管理这些配额成了噩梦。
CLIProxyAPI的核心价值在于统一接口和智能路由。它提供兼容OpenAI、Anthropic、Gemini、Codex、Grok的API接口,让任何支持自定义Base URL的AI编程工具或SaaS业务后端,都能通过同一个代理访问所有AI服务。
为什么选择CLIProxyAPI而不是Sub2API?
在寻找API统一解决方案时,你可能也遇到过Sub2API。两者都是优秀的工具,但我最终选择了CLIProxyAPI,原因如下:
架构设计理念不同:
- Sub2API:更偏向于传统的API网关,专注于请求转发和格式转换
- CLIProxyAPI:专为AI编程工具生态设计,深度集成OAuth登录、配额管理、模型别名等AI特有功能
OAuth登录体验:
- Sub2API:需要手动获取API密钥,然后配置到网关
- CLIProxyAPI:提供一键登录命令(
--claude-login、--codex-login等),浏览器自动弹出,认证流程无缝
配额智能管理:
- Sub2API:需要外部监控和手动切换
- CLIProxyAPI:内置配额检测,支持
round-robin和fill-first策略,配额用尽自动切换账户或降级到预览模型
模型生态支持:
- CLIProxyAPI:原生支持Claude Code、Codex、Gemini CLI、Antigravity、Kimi等AI编程工具的专属模型
- Sub2API:更通用,但对这些AI工具的特殊需求支持较少
配置热重载:
- CLIProxyAPI:修改配置无需重启服务,立即生效
- Sub2API:通常需要重启才能应用新配置
轻量级部署:
- CLIProxyAPI:单个10MB二进制文件,内存占用<10MB
- Sub2API:相对更重,依赖更多
如果你只需要基础的API转发,Sub2API足够用。但如果你深度使用多个AI编程工具,或者希望把Codex、Antigravity这类账户能力统一暴露给自己的SaaS业务使用,需要智能配额管理、一键登录、模型别名等高级功能,CLIProxyAPI是更专业的选择。
5分钟快速上手:接入Codex和Antigravity
先花5分钟跑通一个真实场景:把Codex和Antigravity接入CLIProxyAPI,然后通过统一Base URL调用文本模型和生图模型。
第一步:下载安装
去GitHub Releases下载对应系统的包:
- macOS Apple Silicon:
darwin_arm64 - macOS Intel:
darwin_amd64 - Linux:
linux_amd64 - Windows:
windows_amd64.zip
解压到一个干净目录,比如
~/CLIProxyAPI/。解压后确认目录里有可执行文件cli-proxy-api,后续命令都在这个目录下执行。第二步:配置基础文件
解压后目录里有一个
config.example.yaml。复制一份改名config.yaml,清空内容,换成这几行:port: 8317
auth-dir: "~/.cli-proxy-api"
request-retry: 3
quota-exceeded:
switch-project: true
switch-preview-model: true
api-keys:
- "ABC-123456"
这里的
api-keys是你自己设的密码,客户端或SaaS后端连代理时要带。auth-dir是OAuth登录后认证文件的存放位置。第三步:登录Codex和Antigravity
打开终端,cd到CLIProxyAPI所在目录,分别执行登录命令:
cd ~/CLIProxyAPI
# 登录Codex
./cli-proxy-api --codex-login
# 登录Antigravity
./cli-proxy-api --antigravity-login
浏览器会自动弹出登录页,按提示完成授权。终端会让你给账户起名字,比如
codex-main、antigravity-main,回车后认证文件就会保存到auth-dir目录。第四步:启动代理
./cli-proxy-api
看到
API server started successfully on: :8317就成了。第五步:验证连接
curl http://127.0.0.1:8317/v1/models -H "Authorization: Bearer ABC-123456"
返回里能看到已接入账户暴露出来的可用模型,说明代理已经正常工作。后续无论是文本模型还是生图模型,都可以通过这个统一入口调用。
连接你的AI编程工具和SaaS业务
现在可以把各种AI编程工具接上来了。核心思路都一样:把工具的Base URL指向
http://127.0.0.1:8317。Claude Code配置:
export ANTHROPIC_BASE_URL=http://127.0.0.1:8317
export ANTHROPIC_AUTH_TOKEN=ABC-123456
export ANTHROPIC_DEFAULT_SONNET_MODEL=你的文本模型名
claude
其他工具配置:
- Cherry Studio:添加提供商 → 类型选
OpenAI-Response→ API密钥填ABC-123456→ API地址填http://127.0.0.1:8317 - Cline / Roo Code:Provider选
OpenAI Compatible→ Base URL填http://127.0.0.1:8317/v1→ API Key填ABC-123456 - Cursor:OpenAI API Base URL填
http://127.0.0.1:8317/v1 - Continue:在VSCode Continue扩展设置中配置
SaaS业务接入:
如果你的业务后端原来调用的是OpenAI兼容接口,只需要把Base URL改成CLIProxyAPI地址,API Key改成你在
config.yaml里配置的api-keys即可。BASE_URL=http://127.0.0.1:8317/v1
API_KEY=ABC-123456
这样你的SaaS业务就可以通过同一个代理调用文本模型和生图模型,不再需要额外购买或依赖第三方API中转服务。
进阶玩法:多账户智能混搭
一个Codex或Antigravity账户可能不够。真正的威力在于把所有订阅塞进同一个代理。
添加更多提供商:
# 添加Claude Code订阅
./cli-proxy-api --claude-login
# 添加OpenAI Codex订阅
./cli-proxy-api --codex-login
# 添加Gemini订阅(需要Google Cloud项目)
./cli-proxy-api --login --project_id "你的项目ID"
# 添加Antigravity
./cli-proxy-api --antigravity-login
# 添加Kimi
./cli-proxy-api --kimi-login
所有登录命令都支持
--no-browser(不自动打开浏览器)和--oauth-callback-port 9999(自定义回调端口)。智能路由配置:
在Claude Code中,你可以这样混搭不同模型:
# 重活用Claude,日常用Gemini,轻量任务用Codex
export ANTHROPIC_DEFAULT_OPUS_MODEL=claude-opus-4-6
export ANTHROPIC_DEFAULT_SONNET_MODEL=gemini-2.5-pro
export ANTHROPIC_DEFAULT_HAIKU_MODEL=gpt-5-codex-mini
客户端请求哪个模型,CLIProxyAPI就自动路由到对应的提供商。格式转换、认证方式全自动处理。
对于SaaS业务来说,也可以把不同用途的模型拆开:文本生成走文本模型,图片生成走生图模型,但底层都通过同一个CLIProxyAPI地址完成调用。
多账户轮询策略:
如果你有多个同类型账户,可以配置轮询策略:
routing:
strategy: "round-robin" # 每次请求换一个账户
# strategy: "fill-first" # 优先用第一个账户直到满
round-robin把请求均匀分配到所有账户,适合多号分摊配额。fill-first优先压一个号,适合"主力号 + 备用号"的组合。服务器部署:给SaaS业务提供统一代理
本地跑通了,下一步是丢到服务器上,让团队多台设备或SaaS后端共用一个代理。
Docker部署方案:
创建
docker-compose.yml:services:
cli-proxy-api:
image: eceasy/cli-proxy-api:latest
pull_policy: always
container_name: cli-proxy-api
ports:
- "8317:8317" # 主API端口
- "8085:8085" # Gemini OAuth回调
- "1455:1455" # Codex OAuth回调
- "54545:54545" # Claude OAuth回调
volumes:
- ./config.yaml:/CLIProxyAPI/config.yaml
- ./auths:/root/.cli-proxy-api
- ./logs:/CLIProxyAPI/logs
restart: unless-stopped
启动容器:
docker compose up -d
远程OAuth登录技巧:
容器里没浏览器,用SSH隧道解决。以Codex为例:
# 服务器上
docker compose exec cli-proxy-api /CLIProxyAPI/cli-proxy-api --no-browser --codex-login
# 本地电脑上(新终端)
ssh -L 1455:localhost:1455 user@你的服务器IP
# 然后在本地浏览器打开服务器输出的链接
如果你要接入Antigravity,也可以用同样思路执行:
docker compose exec cli-proxy-api /CLIProxyAPI/cli-proxy-api --no-browser --antigravity-login
接入第三方API中转服务
除了OAuth登录"借用"订阅,你也可以直接用API Key接入官方API或中转服务商。不过在我自己的使用场景里,Codex和Antigravity接入后已经能覆盖文本模型和生图模型调用,SaaS业务可以直接走自建CLIProxyAPI,因此不再需要市面上的API中转服务。
Claude API配置:
claude-api-key:
# 官方API,不需要base-url
- api-key: "sk-ant-...你的密钥"
# 中转商,需要指定base-url
- api-key: "sk-xxx..."
base-url: "https://中转商地址/api"
Gemini API(AIStudio)配置:
gemini-api-key:
- api-key: "AIzaSy..."
models:
- name: "gemini-2.5-flash"
alias: "flash" # 短别名,可选
OpenAI兼容服务(如OpenRouter):
openai-compatibility:
- name: "openrouter"
base-url: "https://openrouter.ai/api/v1"
api-key-entries:
- api-key: "sk-or-v1-...密钥1"
- api-key: "sk-or-v1-...密钥2" # 多密钥自动轮询
models:
- name: "moonshotai/kimi-k2:free"
alias: "kimi-k2"
高级功能:按需使用
模型别名管理:
嫌模型名太长?起个短名:
oauth-model-alias:
gemini-cli:
- name: "gemini-2.5-pro"
alias: "g2.5p"
fork: true # 保留原名的同时多一个别名
排除特定模型:
不想暴露某些模型给客户端:
oauth-excluded-models:
gemini-cli:
- "*-preview"
- "*flash*"
请求参数默认值:
给特定模型强制设参数:
payload:
default:
- models:
- name: "gemini-2.5-pro"
params:
"generationConfig.thinkingConfig.thinkingBudget": 32768
避坑指南:常见问题解决
1. 改了配置要重启吗?
不用,热重载。唯一例外是
remote-management配置。2. 怎么看有哪些可用模型?
curl http://127.0.0.1:8317/v1/models -H "Authorization: Bearer 你的key"
3. Claude API请求被拒绝?
从非官方客户端调用Claude API可能被拒。开启Cloak伪装:
claude-api-key:
- api-key: "sk-ant-..."
cloak:
mode: "auto" # 非Claude Code客户端自动伪装请求头
4. 配额满了怎么办?
CLIProxyAPI自动处理:
switch-project: true:配额满了自动换账户switch-preview-model: true:所有号都满了,尝试切到预览版模型
5. 多设备共享认证?
在
.env里配远程存储,支持PostgreSQL、Git仓库、S3三种方案。总结:为什么CLIProxyAPI是AI开发者和SaaS业务的必备工具
在AI工具碎片化的今天,CLIProxyAPI提供了一个统一的解决方案。它不仅仅是API代理,更是AI工作流的中枢神经系统。
对个人开发者,它让你:
- 用一个接口访问所有AI服务
- 智能管理多个账户配额
- 在不同AI编程工具间无缝切换
对团队和SaaS业务,它提供:
- 统一的API网关
- 集中式的配额管理
- 文本模型和生图模型的统一接入
- 可审计的使用统计
对效率追求者,它意味着:
- 不再手动切换账户
- 配额用尽自动切换
- 模型调用透明路由
- 不再依赖市面上的API中转服务
CLIProxyAPI的开源本质意味着你可以完全掌控自己的AI工作流。它不依赖任何商业中转服务,所有数据都在本地或你自己的服务器上。
现在,当你面对Claude Code、Codex、Gemini、Antigravity等割裂生态时,你有了更好的选择:一个代理,统一所有。
从今天开始,告别API割裂时代,也告别第三方API中转依赖。